SpringCloud
SpringCloud 和 SpringCloud Alibaba
SpringCloud和SpringCloud Alibaba都是微服务架构中的重要工具,它们各自具有独特的特点和优势。以下是对这两者的详细比较:
一、定义与背景
- SpringCloud
- SpringCloud是基于SpringBoot的一整套实现微服务的框架。
- 它提供了微服务开发所需的配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、分布式会话和集群状态管理等组件。
- SpringCloud是Spring社区开发的一套微服务架构框架,为开发者构建分布式系统提供了多种解决方案。
- SpringCloud Alibaba
- SpringCloud Alibaba是阿里巴巴提供的微服务开发一站式解决方案,是阿里巴巴开源中间件与SpringCloud体系的融合。
- 它包含了开发分布式应用微服务的必需组件,方便开发者轻松使用这些组件来开发分布式应用服务。
- 作为SpringCloud体系下的新实现,SpringCloud Alibaba具备了更多的功能,旨在为企业级应用提供全面的支持。
二、核心组件与功能
- SpringCloud
- 核心组件:Eureka(服务发现)、Ribbon(负载均衡)、Feign(声明式的Web服务客户端)、Hystrix(断路器)、Zuul(网关)等。
- 功能:服务发现与注册、配置中心、消息总线、负载均衡、断路器、数据监控等。
- SpringCloud Alibaba
- 核心组件:Nacos(服务发现与配置管理)、Sentinel(流量控制、熔断降级)、RocketMQ(分布式消息队列)、Dubbo(高性能RPC框架)、Seata(分布式事务解决方案)等。
- 功能:除了包含SpringCloud的核心功能外,还提供了更多的企业级支持,如分布式事务、数据库连接池优化等。
三、主要区别
- 组件与工具
- SpringCloud提供了一系列的组件和工具,这些组件和工具都是Spring官方提供的标准解决方案。
- SpringCloud Alibaba则更侧重于为企业级应用提供全面的支持,包括对微服务架构、分布式事务等的深度集成,并提供了丰富的生态系统。
- 云服务支持
- SpringCloud本身并不直接支持阿里云服务。
- SpringCloud Alibaba则内置了对阿里云一系列服务(如RDS、OSS、Sentinel等)的无缝对接,使得开发者能够更容易地利用这些云服务。
- 本地化调整
- SpringCloud是一个国际化的框架,适用于全球范围内的开发者。
- SpringCloud Alibaba则针对中国市场做了很多本地化的调整,比如对中文文档的支持、适配国内法规等。
四、使用场景与选择建议
- 使用场景
- SpringCloud适用于需要快速构建微服务架构、对云服务没有特定要求、或者希望使用Spring官方提供的标准组件和工具的开发者。
- SpringCloud Alibaba适用于在中国市场部署应用、需要充分利用阿里云的服务、或者希望使用阿里巴巴提供的微服务解决方案和最佳实践的开发者。
- 选择建议
- 在选择SpringCloud或SpringCloud Alibaba时,需要根据具体的应用场景和需求进行权衡。
- 如果应用需要在中国市场部署,并且希望充分利用阿里云的服务,那么SpringCloud Alibaba可能是更好的选择。
- 如果应用对云服务没有特定要求,或者希望使用Spring官方提供的标准组件和工具,那么SpringCloud也是一个不错的选择。
综上所述,SpringCloud和SpringCloud Alibaba都是优秀的微服务框架,但它们各有特点。在选择时,需要根据具体的应用场景和需求进行权衡,以选择最适合自己的框架。
SpringCloud、SpringCloud Alibaba 和 SpringBoot 兼容性
SpringCloud Alibaba、SpringCloud 和 SpringBoot 兼容性列表https://github.com/alibaba/spring-cloud-alibaba/wiki/%E7%89%88%E6%9C%AC%E8%AF%B4%E6%98%8E
SpringCloud 和 SpringBoot 兼容性列表https://stackoverflow.com/questions/42659920/is-there-a-compatibility-matrix-of-spring-boot-and-spring-cloud
访问https://spring.io/projects/spring-cloud,通过ctrl+f搜索Table 1. Release train Spring Boot compatibility定位到spring-cloud和spring-boot兼容表格
| Release Train | Boot Version |
|---|---|
| 2023.0.x aka Leyton | 3.3.x, 3.2.x |
| 2022.0.x aka Kilburn | 3.0.x, 3.1.x (Starting with 2022.0.3) |
| 2021.0.x aka Jubilee | 2.6.x, 2.7.x (Starting with 2021.0.3) |
| 2020.0.x aka Ilford | 2.4.x, 2.5.x (Starting with 2020.0.3) |
| Hoxton | 2.2.x, 2.3.x (Starting with SR5) |
| Greenwich | 2.1.x |
| Finchley | 2.0.x |
| Edgware | 1.5.x |
| Dalston | 1.5.x |
| Camden | 1.4.x |
| Brixton | 1.3.x, 1.4.x |
| Angel | 1.2.x |
SpringCloud 作用
SpringCloud是一个微服务框架,是能快速构建分布式系统的工具,其作用主要体现在以下几个方面:
一、提供微服务架构解决方案
SpringCloud利用Spring Boot的开发便利性,简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用Spring Boot的开发风格做到一键启动和部署。它并没有重复制造轮子,而是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装,屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
二、核心组件及其作用
- 服务发现和注册:如Eureka,它允许微服务实例动态地注册到服务注册中心,并且允许客户端查询可用服务实例的详细信息,从而实现服务的自动发现。这有助于微服务架构中的服务自动化部署和故障转移。
- 负载均衡:如Ribbon,它提供客户端的负载均衡功能,可以在多个微服务实例之间分配请求,以提高系统的吞吐量和可用性。
- 配置管理:如Spring Cloud Config,它允许将配置信息外部化,并集中管理。通过配置服务器,可以轻松地管理不同环境(如开发、测试、生产)的配置信息,支持配置的动态刷新。
- API网关:如Spring Cloud Gateway,它作为微服务架构中的单一入口点,负责路由转发、身份验证、监控等功能。它可以帮助开发者简化客户端与微服务之间的通信,并提供额外的安全层。
- 事件总线:Spring Cloud Bus,它允许微服务之间通过消息传递机制进行通信,可以基于消息中间件(如RabbitMQ、Kafka)实现,支持事件的发布/订阅模式。
三、增强微服务架构的可靠性
SpringCloud提供了多种工具和组件来增强微服务架构的可靠性,如断路器(如Hystrix)、智能路由、集群状态监控等。这些功能可以帮助开发者及时发现和处理微服务架构中的故障,提高系统的稳定性和可用性。
四、支持多种部署环境和平台
SpringCloud支持多种部署环境和平台,包括云平台、容器化平台等。它提供了与这些平台的集成支持,使得微服务应用可以更加灵活地部署和扩展。
五、持续更新和优化
SpringCloud作为一个开源项目,一直在不断地更新和优化。随着微服务架构的不断发展,SpringCloud也在不断地引入新的功能和改进,以满足开发者的需求。例如,在最近的更新中,Spring Cloud Gateway引入了gRPC路由的原生支持,提高了微服务之间的通信效率;Spring Cloud Config增强了与多云环境的兼容性,提高了配置管理的灵活性和安全性。
综上所述,SpringCloud在微服务架构中发挥着至关重要的作用,它提供了一套完整的工具和组件来帮助开发者构建、部署和管理微服务应用。
服务注册与发现
定义
微服务服务注册与发现是微服务架构中的核心组件,它解决了微服务实例动态变化所带来的挑战,使得服务间能够高效地相互找到并进行通信。以下是对微服务服务注册与发现的详细解析:
一、基本概念
- 服务注册(Service Registration):
- 定义:服务提供者将自己的元数据信息(如主机和端口号、身份验证信息、协议、版本号以及运行环境的信息等)注册到服务注册中心的过程。
- 目的:使服务注册中心能够记录和追踪所有可用的服务实例。
- 服务发现(Service Discovery):
- 定义:服务消费者(客户端)在需要调用服务时,通过查询服务注册中心获取服务提供者的服务实例信息的过程。
- 目的:使服务消费者能够动态地获取服务实例信息,无需预先知道服务提供者的具体地址。
二、工作模式
微服务服务注册与发现主要有两种工作模式:
- 自注册模式(客户端/直连模式):
- 服务消费者直接与注册中心交互,获取服务提供者的地址信息。
- 优点:直接控制服务发现过程。
- 缺点:需要修改代码,对跨平台支持不够友好。
- 代理模式(服务端模式):
- 服务消费者通过一个代理(如API网关或服务发现代理)来获取服务提供者的地址信息。
- 优点:跨平台友好,易于维护。
- 缺点:增加了代理服务的复杂性和可能的性能开销。
三、关键技术
- 服务注册中心的设计与实现:
- 数据存储:服务注册中心需要能够存储大量的服务实例信息,因此需要一个高效、可扩展的数据存储系统。
- 网络通信:服务注册中心需要能够处理大量的网络请求,包括服务注册请求、服务发现请求以及健康检查请求等。
- 服务健康检查:服务注册中心需要定期对注册的服务进行健康检查,以确认服务是否还在运行。
- 高可用/分布式:在分布式架构中,服务注册中心的高可用性至关重要。通过合理选择一致性、可用性和分区容错性的平衡点,可以优化服务注册与发现的性能和可靠性。
- 服务发现机制的设计与实现:
- 服务查询:服务发现机制需要能够根据服务名称查询出对应的服务实例信息。
- 负载均衡:在多个相同的服务实例中,服务发现机制需要能够选择一个合适的实例进行调用。
- 服务降级与熔断:当被调用的服务出现故障时,服务发现机制需要能够进行服务降级或者熔断,以保证系统的稳定性。
四、常用工具与框架
- Eureka:
- 简介:Eureka是Netflix开源的一款提供服务注册和发现的产品,也是Spring Cloud体系中的重要组件之一。
- 优点:与Spring Cloud集成良好,使用和配置简单,具有自我保护机制。
- 缺点:自我保护模式可能会让客户端获取到不可用的服务实例信息,不支持跨语言,只能在Java环境中使用。
- Zookeeper:
- 简介:Zookeeper是Apache的一个开源项目,提供配置维护、域名服务、分布式同步、组服务等功能。
- 优点:提供了一种中心化的服务,用于维护配置信息、命名、提供分布式同步和提供组服务。
- 缺点:CP特性使其在出现网络分区时可能无法提供服务,API使用起来相对复杂,学习成本较高。
- Consul:
- 简介:Consul是HashiCorp公司推出的开源工具,用于实现分布式系统的服务发现与配置。
- 优点:内置了服务注册与发现框架,支持健康检查,并且支持多数据中心。
- 缺点:一些高级功能的使用和配置相对复杂。
- Etcd:
- 简介:Etcd是一个开源的、基于Raft协议的分布式键值存储系统,由CoreOS开发,主要用于共享配置和服务发现。
- 优点:使用Raft协议保证了数据的一致性,支持SSL保证了数据的安全性。
- 缺点:性能相比Zookeeper和Consul要差一些。
- Nacos:
- 简介:Nacos是阿里巴巴开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
- 优点:支持几乎所有主流类型的服务的发现、配置和管理,更加适合云原生应用场景;提供了简单易用的UI界面;支持数据持久化,避免了数据的丢失。
- 缺点:是阿里巴巴内部使用的产品,对于一些特定的业务场景可能需要进行定制化开发。
五、实现流程
- 服务注册流程:
- 服务启动时,向注册中心发送注册请求。
- 注册中心接收到注册请求后,存储服务的元数据(如服务名、地址、端口、版本等)。
- 注册中心定期更新服务的状态,确保服务的可用性。
- 服务发现流程:
- 客户端在需要调用某个服务时,首先向注册中心请求该服务的实例列表。
- 注册中心将活跃的服务实例列表返回给客户端。
- 客户端选择一个可用的服务实例进行调用。
六、总结
微服务服务注册与发现是微服务架构中不可或缺的重要组成部分。通过服务注册与发现,服务实例能够动态地注册到注册中心,并在需要时被服务消费者发现。这大大提高了微服务架构的灵活性和可扩展性。在选择服务注册与发现的工具或框架时,需要根据具体业务需求和技术架构进行综合考虑。
CAP 定理
https://cloud.tencent.com/developer/article/2429547
CAP定理由如下三部分组成。
- C(Consistency),一致性。每次对数据的读取都是最近一次写入的内容;
- A(Availability),可用性。每次请求读取数据都能成功读取到数据,但读取到的数据不保证总是最近一次写入的内容;
- P(Partition tolerance),分区容错性。网络节点之间可能发生网络故障从而导致消息丢失,但这不会影响系统的运行。
CAP里面的C和A都比较好理解,P好像有点抽象,其实这么理解就对了,P的意思就是允许存在网络故障。
对于一个分布式数据存储系统来说,如果没有网络故障,那么CAP的 三个特性都是可以满足 的。
但分布式系统的 网络故障一定是不可避免的,所以P是一定要满足的,并且此时C和A只能满足一个,因此就出现了CP模型和AP模型。
假设我们现在有如下这么一个分布式数据存储系统。
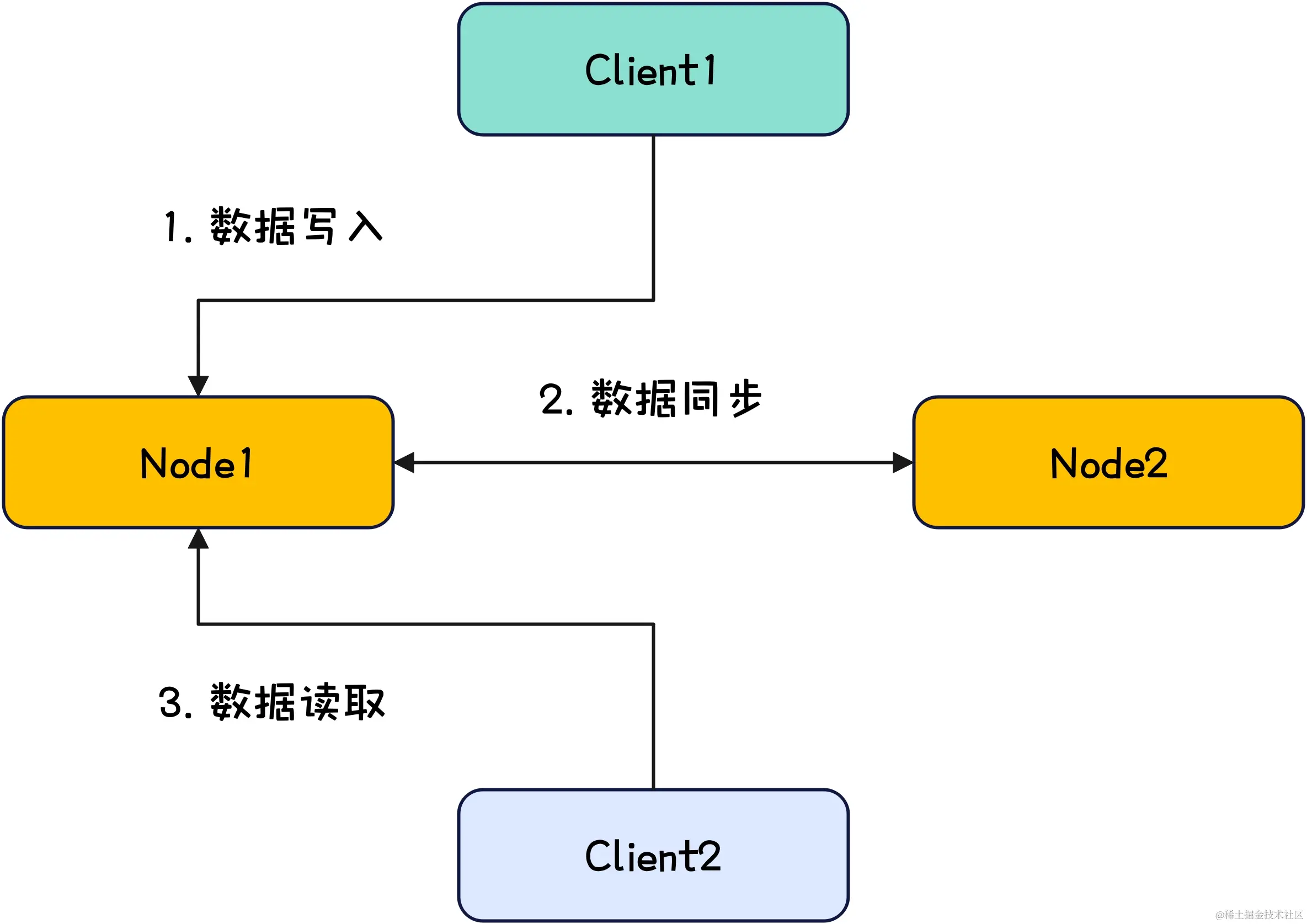
当数据同步因为网络问题而无法实现时,下面来分别看下CP模型和AP模型的行为是什么。
在CP模型下,因为要满足C的一致性,所以一旦网络出现问题导致数据同步失败,此时数据的读取就会被拒绝从而导致读取超时或失败,这种情况下,系统变得不可用,即A不满足。
在AP模型下,因为要满足A的可用性,所以就算网络出现问题导致数据同步失败,此时数据的读取还是能够成功读取到数据,但这种情况下节点间的数据是不同的,即C不满足。
总结
CAP的C表示一致性,要求节点间的数据要完成数据同步。
CAP的A表示可用性,要求系统对外随时都能提供数据读取的服务。
CAP的P表示分区容错性,要求系统能够在存在网络故障的情况下运行。
因为分布式系统中网络故障是一定会存在的,所以P是一定要满足的,并且C和A是一定无法同时满足的,此时就形成了CP模型和AP模型。
CP模型在网络发生故障时会拒绝对外提供数据读取服务,此时A也就是可用性无法满足。
AP模型在网络发生故障时还是会对外提供服务,但节点间的数据会不一致,此时C也就是一致性无法满足。
在Nacos中,对于临时实例的服务实例信息获取,Nacos采用AP模型,具体的实现采用Distro协议,而对于持久化实例,Nacos采用CP模型,具体的实现采用SOFAJRaft协议。
Eureka、Zookeeper、Consul、Nacos 分别是 AP 还是 CP 呢?
Eureka、Zookeeper、Consul、Nacos都是分布式系统中的服务注册与发现组件,它们在CAP(一致性Consistency、可用性Availability、分区容错性Partition Tolerance)理论中的表现各不相同。以下是这四个组件的CAP特性概述:
Eureka
- 一致性(C):Eureka更注重可用性和容错性,因此在一致性方面可能有所妥协。在部分节点失效的情况下,Eureka仍能保证服务注册与发现机制的可用性,但数据的新鲜度可能会受到影响。
- 可用性(A):Eureka具有高可用性,确保服务的连续性。即使部分节点失效,只要还有Eureka存活,服务注册与发现机制就能继续工作。
- 分区容错性(P):Eureka具备分区容错性,能够在网络分区或节点故障时保持系统的可用性。
Zookeeper
- 一致性(C):Zookeeper侧重于一致性和容错性。它使用ZAB(Zookeeper Atomic Broadcast)协议确保数据一致性,即使在选举新Leader时会有短暂的不可用性,但一旦完成,数据一致性得到保障。
- 可用性(A):虽然Zookeeper在一致性方面表现出色,但在可用性方面可能略逊于Eureka。在选举新Leader期间,系统可能会暂时不可用。
- 分区容错性(P):Zookeeper具备分区容错性,能够在网络分区或节点故障时保持系统的运行。
Consul
- 一致性(C):Consul在CAP理论中偏向CP,但也会适时调整以维持可用性。它提供了强大的服务注册与发现能力,以及细致入微的健康检查功能。
- 可用性(A):虽然Consul在一致性方面有所保障,但在可用性方面可能受到一定影响,尤其是在进行领导节点选举或数据同步时。
- 分区容错性(P):Consul具备分区容错性,能够在网络分区或节点故障时保持系统的可用性。
Nacos
- 一致性(C)与可用性(A):Nacos灵活地在CP和AP间切换。对于持久化实例,Nacos使用CP架构;对于临时实例,则使用AP架构。这种灵活性使得Nacos能够在不同场景下提供最佳的性能和可用性。
- 分区容错性(P):Nacos具备分区容错性,能够在网络分区或节点故障时保持系统的可用性。
总结来说,Eureka、Zookeeper、Consul和Nacos在CAP理论中的表现各有侧重。Eureka更注重可用性和容错性;Zookeeper侧重于一致性和容错性;Consul在一致性和可用性之间取得平衡;而Nacos则灵活地在CP和AP间切换,以适应不同的应用场景。在选择这些组件时,应根据项目的具体需求、系统性能、团队技术水平和未来规划进行综合考虑。
Eureka
注意:停止更新,将会抛弃
单机版
https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-eureka
启动示例中相关应用
访问http://localhost:9999/查看 Eureka 面板
集群版
https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-eureka-cluster参考资料
https://blog.csdn.net/weixin_43907332/article/details/94473626
编辑 /etc/hosts 添加以下内容
127.0.0.1 abc1.com
127.0.0.1 abc2.com
127.0.0.1 abc3.com启动示例中相关应用
分别访问 Eureka 面板,面板中 DS Replicas 会显示其他 Eureka 节点,http://localhost:9999/、http://localhost:10000/、http://localhost:10001/
关闭其中两台 Eureka 后重启 zuul 和 helloworld 服务,访问如下 url 服务依旧正常,http://localhost:8080/api/v1/sayHello
基本配置
Eureka 服务端配置
eureka.instance.hostname=${spring.application.name}
# 由于该应用为注册中心,所以设置为false,代表不向注册中心注册自己
eureka.client.register-with-eureka=false
# 用于指定Eureka客户端不需要从Eureka服务器获取服务注册信息,这通常适用于Eureka服务器节点本身或在某些特殊场景下不需要知道其他服务位置的客户端。
eureka.client.fetch-registry=false
# 作用是让Eureka客户端知道它应该连接到哪个Eureka服务器来注册自己或发现其他服务
eureka.client.serviceUrl.defaultZone=http://localhost:${server.port}/eureka/
# 服务端是否开启自我保护机制 (默认true)
eureka.server.enable-self-preservation=false
# 将 eureka.server.eviction-interval-timer-in-ms 设置为2000毫秒意味着Eureka服务器将每2秒检查一次已注册的服务实例,
# 如果发现某个实例在一定时间内(这个时间由 eureka.instance.lease-expiration-duration-in-seconds 配置项设置)没有发送心跳信号(表示该实例仍然活跃),
# 则Eureka服务器将认为这个实例已经失效,并将其从服务注册表中移除。
eureka.server.eviction-interval-timer-in-ms=30000Eureka 客户端配置
# 作用是让Eureka客户端知道它应该连接到哪个Eureka服务器来注册自己或发现其他服务
eureka.client.serviceUrl.defaultZone=http://localhost:9999/eureka/
# eureka实例面板显示的实例标识
eureka.instance.instance-id=zuul1
# eureka实例面板显示实例的主机ip
eureka.instance.prefer-ip-address=true
# 客户端向注册中心发送心跳的时间间隔,(默认30秒)
eureka.instance.lease-renewal-interval-in-seconds=10
# eureka注册中心(服务端)在收到客户端心跳之后,等待下一次心跳的超时时间,如果在这个时间内没有收到下次心跳,则移除该客户端。(默认90秒)
eureka.instance.lease-expiration-duration-in-seconds=30禁用自我保护机制
Eureka的自我保护机制是Eureka注册中心的一个重要特性,旨在提高分布式系统的可用性和容错性,特别是在网络分区或网络不稳定的情况下。以下是关于Eureka自我保护机制的详细解释:
一、机制概述
Eureka的自我保护机制是为了防止在网络问题导致服务注册中心错误地剔除健康的服务实例,从而造成更大的系统故障。在网络异常情况下,Eureka会进入自我保护模式,暂停从注册表中移除因心跳丢失而被认为不可用的服务实例,尽量保证服务发现的可用性。
二、工作原理
- 心跳机制:Eureka客户端会定期(默认每30秒)向Eureka服务器发送心跳信号,以证明该实例仍然处于健康状态。
- 心跳检测:Eureka服务器会定期检测各个服务实例的心跳信号。如果某个服务实例在一定时间内(默认90秒)没有发送心跳,Eureka服务器通常会将该实例从注册表中移除。
- 自我保护模式触发条件:Eureka服务器会计算最近15分钟内收到的心跳的比例(实际收到的心跳与理论上应该收到的心跳数量的比值)。如果Eureka发现接收到的心跳数量突然下降到低于一个阈值(通常是85%),它将进入自我保护模式。
- 自我保护模式下的行为:在自我保护模式下,Eureka服务器将不会从注册表中移除因心跳丢失而被认为不可用的服务实例,即使这些实例实际上可能已经停止发送心跳。这样做是为了防止由于网络抖动等原因导致的误删健康的服务实例,从而保证了服务的高可用性和稳定性。
三、自我保护模式的解除
当网络状况恢复正常,Eureka服务器收到的心跳数量恢复到正常水平并持续一段时间后,Eureka会自动退出自我保护模式,并恢复正常的服务实例剔除机制。这一过程是自动的,不需要人工干预。
四、自我保护机制的可配置性
Eureka的自我保护机制是可配置的。通过修改Eureka服务器配置文件中的相关参数,可以调整何时触发自我保护模式,或者完全关闭此功能。例如,可以通过修改eureka.server.enable-self-preservation的配置值来开启或关闭自我保护模式。然而,在生产环境中通常建议开启自我保护模式,以确保在网络不稳定的情况下Eureka注册中心的稳定性不被破坏。
五、注意事项
- 自我保护机制虽然提高了系统的容错性,但也可能导致注册表中存在一些已经失效的服务实例。因此,在生产环境中,如果发现自我保护模式频繁启动,就需要进一步排查网络或其他问题,并及时修复。
- 在自我保护模式下,Eureka的注册表中可能会包含一些已经不可用的服务实例信息,这可能导致服务发现的结果不准确。因此,在使用Eureka时需要注意这一点。
综上所述,Eureka的自我保护机制是一种重要的安全保护措施,它通过在网络异常情况下暂停剔除失效的服务实例来保护注册表的稳定性。这一机制提高了分布式系统的可用性和容错性,使得服务消费者在网络故障恢复后仍然能够发现和调用服务实例。
一旦 Eureka 客户端没有心跳约在一分钟内从 Eureka 实例列表剔除
Eureka 服务端配置
# 服务端是否开启自我保护机制 (默认true)
eureka.server.enable-self-preservation=false
# 将 eureka.server.eviction-interval-timer-in-ms 设置为2000毫秒意味着Eureka服务器将每2秒检查一次已注册的服务实例,
# 如果发现某个实例在一定时间内(这个时间由 eureka.instance.lease-expiration-duration-in-seconds 配置项设置)没有发送心跳信号(表示该实例仍然活跃),
# 则Eureka服务器将认为这个实例已经失效,并将其从服务注册表中移除。
eureka.server.eviction-interval-timer-in-ms=30000Eureka 客户端配置
# 客户端向注册中心发送心跳的时间间隔,(默认30秒)
eureka.instance.lease-renewal-interval-in-seconds=10
# eureka注册中心(服务端)在收到客户端心跳之后,等待下一次心跳的超时时间,如果在这个时间内没有收到下次心跳,则移除该客户端。(默认90秒)
eureka.instance.lease-expiration-duration-in-seconds=30Zookeeper
注意:用得少,所以不做实验
Consul
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-consul-parent
启动 Consul 服务
docker-compose up -d访问http://localhost:8500/,检查 Consul 服务器是否正常
启动所有应用
访问http://localhost:8081/api/v1/a/sayHello?name=Dexter以测试应用服务是否正常
Nacos
注意:阿里巴巴主流注册中心
详细用法请参考文档 链接
服务调用和负载均衡
Ribbon
注意:停止更新,许多遗留项目还在使用,所以需要学习。
Ribbon 实现客户端的负载均衡
http://www.cnblogs.com/chry/p/7263281.html
进程内负载均衡(负载均衡 + RestTemplate )。
运行示例
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-ribbon-parent
启动 Consul
docker compose up -d启动 ApplicationRibbon、ApplicationHelloworld(修改端口后启动两个 ApplicationHelloworld 应用)
访问http://localhost:8081/api/v1/external/sayHello?name=Dexter测试 Ribbon + RestTemplate 负载均衡。
基本配置
pom 引入 Ribbon 依赖
<!-- SpringCloud Ribbon 客户端依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>RestTemplate 使用 @LoadBalanced 注解
/**
* 无论是否何种Ribbon负载均衡算法都需要配置下面的RestTemplate
* @return
*/
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}使用 IRule 替换负载均衡算法
默认负载均衡算法是 RoundRobinRule
// 注意:自动IRule一定需要放置到与Application启动类所在的包和子包外,例如:com.future.demo.myrule
// 否则@RibbonClient注解不生效
@Configuration
public class MyRuleRandom {
@Bean
public IRule rule() {
// 随机选择服务负载均衡算法
return new RandomRule();
}
}
@SpringBootApplication
@RibbonClient(name = "spring-cloud-helloworld", configuration = MyRuleRandom.class)
@EnableDiscoveryClient
public class ApplicationRibbon {
/**
*
* @param args
*/
public static void main(String[] args) {
SpringApplication.run(ApplicationRibbon.class, args);
}
/**
* 无论是否何种Ribbon负载均衡算法都需要配置下面的RestTemplate
* @return
*/
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
}LoadBalancer
介绍
SpringCloud LoadBalancer是Spring Cloud提供的一个客户端负载均衡器,它取代了传统的Ribbon组件,为微服务架构提供了更加灵活和强大的负载均衡功能。以下是对SpringCloud LoadBalancer的详细解析:
一、定义与职责
负载均衡器(LoadBalancer)是一种网络设备或软件机制,用于分发传入的网络流量负载请求到多个后端目标服务器上,从而实现系统资源的均衡利用和提高系统的可用性和性能。SpringCloud LoadBalancer作为客户端负载均衡器,它的主要职责是根据配置的负载均衡策略,从服务注册中心获取的服务实例列表中选择一个实例来处理请求。
二、工作原理
客户端负载均衡是一种将请求分发到多个服务实例的机制。每个发起服务调用的客户端都存有完整的目标服务地址列表,根据配置的负载均衡策略,由客户端自己决定向哪台服务器发起调用。这种方式相较于传统的网关层负载均衡,具有网络开销小、配置灵活等优点。
在Spring Cloud中,当客户端发起服务调用请求时,请求首先到达带有@LoadBalanced注解的RestTemplate或LBRestTemplate。RestTemplate或LBRestTemplate接收到请求后,会先经过一系列的拦截器(Interceptor)处理,这些拦截器可以用于实现认证、限流等功能。拦截器处理完成后,请求会被传送到LoadBalancer组件。LoadBalancer会根据配置的负载均衡策略和后端服务实例列表,选择一个合适的目标服务器。选定的目标服务器地址将被封装在一个新的HTTP请求中,然后由LoadBalancer将这个新的HTTP请求返回给RestTemplate或LBRestTemplate。最后,RestTemplate或LBRestTemplate将根据LoadBalancer返回的地址信息,直接与服务网关交互并完成服务调用。
三、负载均衡策略
SpringCloud LoadBalancer支持多种负载均衡策略,以满足不同场景的需求。常见的负载均衡策略包括:
- 轮询(Round Robin):按顺序将每个新请求分配给下一个服务器。当到达列表末尾时,它会重新开始。这是最简单的负载均衡策略,适用于服务器性能相似且负载相对均衡的情况。
- 随机(Random):随机选择一个服务器来处理新的请求。适用于服务器数量较多且请求分布均匀的场景。
- 最少连接(Least Connections):选择当前连接数最少的服务器来处理新的请求。这种方法考虑了服务器的当前负载,适用于请求处理时间波动较大的场景。
- 加权轮询(Weighted Round Robin):给每个服务器分配一个权重,服务器的权重越高,分配给该服务器的请求就越多。适用于服务器性能不均或希望给特定服务器更多流量的情况。
- 加权随机(Weighted Random):与加权轮询类似,但是按照权重值来随机选择后端服务器。也可以用来处理后端服务器性能不均衡的情况,但是分发更随机。
- 最短响应时间(Shortest Response Time):测量每个后端服务器的响应时间,并将请求发送到响应时间最短的服务器。这可以确保客户端获得最快的响应,适用于要求低延迟的应用。
- IP哈希(IP Hash):使用客户端的IP地址来计算哈希值,然后将请求发送到与哈希值对应的后端服务器。这种策略可用于确保来自同一客户端的请求都被发送到同一台后端服务器,适用于需要会话保持的情况。
SpringCloud LoadBalancer默认的负载均衡策略是轮询。如果需要自定义负载均衡策略,可以实现ReactorServiceInstanceLoadBalancer接口,并在配置类中注册自定义的负载均衡器。
四、配置与使用
要配置和使用SpringCloud LoadBalancer,需要按照以下步骤进行:
- 添加依赖:确保项目包含SpringCloud LoadBalancer的依赖。如果使用Maven,可以在
pom.xml文件中添加相应的依赖项。 - 创建RestTemplate Bean:在配置类中,创建一个带有
@LoadBalanced注解的RestTemplateBean。这个注解会告诉Spring Cloud使用LoadBalancer来处理该RestTemplate的请求。 - 使用服务名称:在请求URL中使用服务名称而不是具体的IP地址或主机名。例如,如果服务注册在Eureka上,并且服务名称为
my-service,则请求URL应该是http://my-service/some-endpoint。
五、优势与意义
SpringCloud LoadBalancer通过客户端负载均衡的方式,实现了更加高效和灵活的服务调用方式。它具有以下优势:
- 动态配置:支持动态更新配置,当后端服务实例发生变化时,可以快速响应并调整负载均衡策略。
- 健康检查:通过内置的健康检查机制,自动识别并排除故障实例,保证服务的可用性。
- 集成RestTemplate:通过给
RestTemplate打标签的方式,将其转化为经过负载均衡器处理的LBRestTemplate,实现了对现有代码的无侵入式改造。 - 多种负载均衡策略:支持多种负载均衡算法,以满足不同场景的需求。
总之,SpringCloud LoadBalancer是微服务架构中不可或缺的重要组件之一,对于提升系统的性能和稳定性具有重要意义。
运行示例
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-loadbalancer-parent
启动 Consul
docker compose up -d启动 ApplicationLoadBalancer、ApplicationHelloworld(修改端口后启动两个 ApplicationHelloworld 应用)
访问http://localhost:8081/api/v1/external/sayHello?name=Dexter测试 LoadBalancer + RestTemplate 负载均衡。
基本配置
pom 引入 LoadBalancer 依赖
<!-- SpringCloud LoadBalancer 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>RestTemplate 使用 @LoadBalanced 注解
// 创建RestTemplate并开启负载均衡
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}负载均衡算法切换
@Configuration
@LoadBalancerClients(
// spring-cloud-helloworld 使用 LoadBalancerConfig 配置的负载均衡算法 RoundRobinLoadBalancer
@LoadBalancerClient(value = "spring-cloud-helloworld", configuration = LoadBalancerConfig.class))
public class LoadBalancerConfig {
// 创建RestTemplate并开启负载均衡
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
@Bean
ReactorLoadBalancer<ServiceInstance> loadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
// 随机负载均衡算法
/*return new RandomLoadBalancer(loadBalancerClientFactory
.getLazyProvider(name, ServiceInstanceListSupplier.class),
name);*/
// 轮询负载均衡算法
return new RoundRobinLoadBalancer(loadBalancerClientFactory
.getLazyProvider(name, ServiceInstanceListSupplier.class),
name);
}
}OpenFeign
https://www.jianshu.com/p/c0cb63e7640c
定义
OpenFeign是一个声明式的Web服务客户端,它使得编写Web服务客户端变得更加容易。以下是对OpenFeign的详细介绍:
一、简介与背景
OpenFeign是在Spring Cloud生态系统中的一个组件,它整合了Ribbon(客户端负载均衡器)和Eureka(服务发现组件),从而简化了微服务之间的调用。通过定义一个接口并使用注解的方式,开发者可以轻松地创建一个Web服务客户端,而不需要编写大量的模板代码。OpenFeign会自动生成接口的实现类,并使用Ribbon来调用相应的服务。
二、核心组件与功能
OpenFeign的核心组件包括Encoder(编码器)、Decoder(解码器)、Contract(契约)等。这些组件共同协作,实现了对HTTP请求的封装和调用。其中:
- Encoder:负责将请求对象编码为HTTP请求体。
- Decoder:负责将HTTP响应体解码为响应对象。
- Contract:定义了OpenFeign的注解和它们的含义,例如@FeignClient注解用于声明一个Feign客户端。
三、使用与配置
- 添加依赖:在Spring Cloud项目中,使用OpenFeign首先需要添加相应的依赖。通常,这可以通过在pom.xml文件中添加spring-cloud-starter-openfeign依赖来实现。
- 开启OpenFeign:在主应用类上添加@EnableFeignClients注解,以启用OpenFeign的功能。
- 创建Feign客户端接口:通过定义一个接口,并使用@FeignClient注解来指定服务提供者的名称和URL,可以创建一个Feign客户端。在接口中,可以使用Spring MVC的注解来定义需要调用的HTTP方法和路径。
- 配置:OpenFeign提供了多种配置选项,以满足不同的需求。例如,可以通过配置文件或配置类来设置日志级别、连接超时时间和请求处理超时时间等。
四、日志配置
OpenFeign提供了日志打印功能,通过配置调整日志级别,开发者可以了解请求的细节。这有助于在调试和定位问题时获取更多的信息。日志级别包括:
- NONE:不记录任何信息(默认)。
- BASIC:仅记录请求方法、URL以及响应状态码和执行时间。
- HEADERS:除了记录BASIC级别的信息外,还会记录请求和响应的头信息。
- FULL:记录所有请求与响应的明细,包括头信息、请求体、元数据等。
五、超时配置
为了避免服务调用连接和处理时间超时,可以对Feign的连接超时时间和请求处理超时时间进行配置。这可以通过在配置类中定义Request.Options对象,或者在配置文件中指定相关属性来实现。
六、优势与适用场景
OpenFeign的优势在于其易用性、集成性和轻量级特性。它简化了微服务之间的调用,使得开发者可以更加专注于业务逻辑的实现。同时,由于与Spring Cloud的紧密集成,OpenFeign可以方便地利用Spring Cloud提供的各种功能,如熔断、限流等。这使得OpenFeign在构建轻量级的微服务架构时具有显著的优势。
然而,需要注意的是,OpenFeign可能不适合处理大量并发请求或复杂业务场景。在这些情况下,可能需要考虑使用更强大的RPC框架,如Dubbo等。
七、总结
OpenFeign是一个功能强大且易于使用的Web服务客户端,它简化了微服务之间的通信和调用。通过合理的配置和使用,OpenFeign可以帮助开发者构建高效、可靠的微服务架构。
运行示例
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-feign-demo
启动 Consul
docker compose up -d启动 ApplicationEureka、ApplicationConsumer、ApplicationProvider(修改端口后启动两个应用)
访问http://localhost:8080/api/v1/external/product/1测试应用是否正常
基本配置
pom 引用 SpringCloud OpenFeign 依赖
<!-- SpringCloud OpenFeign 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<exclusions>
<!-- 排除 Ribbon 以证明 OpenFeign + Consul 是依赖 SpringCloud LoadBalancer 提供的负载均衡算法支持 -->
<exclusion>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-netflix-ribbon</artifactId>
</exclusion>
</exclusions>
</dependency>创建 OpenFeign 客户端
@FeignClient(
contextId = "productFeign1",
value = "spring-cloud-feign-demo-provider",
path = "/api/v1/product")
public interface ProductFeign {
@GetMapping("{productId}")
ObjectResponse<Product> info(@PathVariable("productId") Integer productId) throws BusinessException;
@GetMapping("get")
Product get(@RequestParam(value = "productId", required = false) Integer productId);
@PostMapping("add")
String add(@RequestHeader(value = "customHeader") String customHeader,
@RequestBody(required = false) Product product);
@GetMapping("timeout")
String timeout();
}Application 中启用 OpenFeign 客户端的支持
@SpringBootApplication
// 应用程序中启用Feign客户端的支持
@EnableFeignClients(
clients = {
ProductFeign.class
}
)
@EnableFutureExceptionHandler
public class ApplicationConsumer {
public static void main(String[] args) {
SpringApplication.run(ApplicationConsumer.class, args);
}
}注入并调用 OpenFeign 客户端
@Resource
ProductFeign productFeign;
@GetMapping("{productId}")
public ObjectResponse<Product> info(@PathVariable("productId") Integer productId) throws BusinessException {
ObjectResponse<Product> response = this.productFeign.info(productId);
return response;
}负载均衡
org.springframework.boot:spring-boot-starter-parent:2.2.7.RELEASE + org.springframework.cloud:spring-cloud-dependencies:Hoxton.SR10 + OpenFeign + Eureka 默认使用 OpenFeign + Ribbon(为 OpenFeign 提供负载均衡算法支持),注意:使用 JMeter 压力测试才能够触发 Ribbon 负载均衡起作用。
org.springframework.boot:spring-boot-starter-parent:2.2.7.RELEASE + org.springframework.cloud:spring-cloud-dependencies:Hoxton.SR10 + OpenFeign + Consul 默认使用 OpenFeign + LoadBalancer(为 OpenFeign 提供负载均衡算法支持)。
访问http://localhost:8080/api/v1/external/product/1测试
超时设置
org.springframework.boot:spring-boot-starter-parent:3.3.7 + org.springframework.cloud:spring-cloud-dependencies:2023.0.4 版本的 OpenFeign 超时设置
# 注意:org.springframework.boot:spring-boot-starter-parent:3.3.7 + org.springframework.cloud:spring-cloud-dependencies:2023.0.4 版本的 OpenFeign 超时设置
# 该属性控制Feign客户端在尝试连接到目标服务时等待响应的最长时间。如果在这个时间内没有成功建立连接,
# 则会抛出超时异常。这有助于防止客户端在目标服务不可用时长时间挂起,从而提高系统的健壮性和响应性。
# default 表示全局 OpenFeign 设置
spring.cloud.openfeign.client.config.default.connect-timeout=75000
# 该属性用于控制服务间调用的响应时间,防止因某个服务响应过慢而导致整个调用链路的阻塞或失败。
# 它确保了Feign客户端在发起远程HTTP请求时,能够根据预设的超时时间限制,及时终止那些响应过慢的请求,从而保护系统的稳定性和响应性。
# default 表示全局 OpenFeign 设置
spring.cloud.openfeign.client.config.default.read-timeout=75000
# 指定 productFeign1 Feign 的超时设置
spring.cloud.openfeign.client.config.productFeign1.connect-timeout=75000
spring.cloud.openfeign.client.config.productFeign1.read-timeout=75000org.springframework.boot:spring-boot-starter-parent:2.2.7.RELEASE + org.springframework.cloud:spring-cloud-dependencies:Hoxton.SR10 版本的 OpenFeign 超时设置
# 注意:org.springframework.boot:spring-boot-starter-parent:2.2.7.RELEASE + org.springframework.cloud:spring-cloud-dependencies:Hoxton.SR10 版本的 OpenFeign 超时设置
feign.client.config.default.connect-timeout=75000
feign.client.config.default.read-timeout=75000访问http://localhost:8080/api/v1/external/product/timeout测试
重试机制
配置如下:
// 设置重试机制
@Bean
Retryer retryer() {
// 不启用重试机制
// return Retryer.NEVER_RETRY;
// 每次重试的时间间隔为 1 秒,period 和 maxPeriod 设置为相等,最大重试次数为 3 次
return new Retryer.Default(1000, 1000, 3);
}访问http://localhost:8080/api/v1/external/product/timeout测试
替换底层使用 HttpClient5 通讯
pom 配置
<!-- 替换底层使用 HttpClient5 通讯依赖 -->
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
</dependency>
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-hc5</artifactId>
</dependency>修改 application.properties 替换 HttpClient5
# 替换底层使用 HttpClient5 通讯
spring.cloud.openfeign.httpclient.hc5.enabled=true访问http://localhost:8080/api/v1/external/product/timeout测试,查看错误堆栈显示使用 HttpClient5 作为底层通讯组件。
日志级别设置
日志级别:
- NONE:不打印日志。
- BASIC:仅记录请求方法和URL以及响应状态码和执行时间。
- HEADERS:记录基本信息以及请求和响应标头。
- FULL:记录请求和响应的标头、正文和元数据。
application.properties 设置日志级别
# 配置 feign 客户端日志级别为 debug(只支持设置为 debug 级别),再配合使用 Logger.Level 设置不同的日志级别
# https://blog.csdn.net/weixin_43472934/article/details/122253068
logging.level.com.future.demo.spring.cloud.feign.common.feign=debugJava 设置日志级别
@Configuration
public class FeignConfig {
// 设置 OpenFeign 日志级别
@Bean
Logger.Level feignLogLevel() {
return Logger.Level.FULL;
}
}访问http://localhost:8080/api/v1/external/product/1测试
启用请求和响应压缩
application.properties 添加配置如下:
# 启用请求和响应压缩
spring.cloud.openfeign.compression.request.enabled=true
spring.cloud.openfeign.compression.response.enabled=true
spring.cloud.openfeign.compression.request.mime-types=text/xml,application/xml,application/json
spring.cloud.openfeign.compression.request.min-request-size=2048访问http://localhost:8080/api/v1/external/product/1测试,如果请求头有 Accept-Encoding: gzip 和 Accept-Encoding: deflate 表示已经启用请求和响应压缩。
自定义请求拦截器并添加请求头和请求参数
定义请求拦截器
/**
* 所有feign调用http头都注入my-header参数
* https://developer.aliyun.com/article/1058305
*/
@Slf4j
public class MyRequestInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
template.header("my-header", "my-value");
// https://stackoverflow.com/questions/559155/how-do-i-get-a-httpservletrequest-in-my-spring-beans
if (RequestContextHolder.getRequestAttributes() != null) {
HttpServletRequest request =
((ServletRequestAttributes) RequestContextHolder.getRequestAttributes())
.getRequest();
String contextUserId = request.getParameter("contextUserId");
if (StringUtils.hasText(contextUserId)) {
template.query("contextUserId", contextUserId);
log.debug("feign客户端成功注入上下文参数,contextUserId={}", contextUserId);
}
}
}
}注入请求拦截器
// 自定义 OpenFeign 请求拦截器
@Bean
RequestInterceptor requestInterceptor() {
return new MyRequestInterceptor();
}访问http://localhost:8080/api/v1/external/product/1测试,查看日志会输出请求头和请求参数值。
Feign 客户端添加请求头
使用 @RequestHeader 注解
https://www.cnblogs.com/laeni/p/12733920.html
@FeignClient(
contextId = "productFeign1",
value = "spring-cloud-feign-demo-provider",
path = "/api/v1/product")
public interface ProductFeign {
@PostMapping("add")
String add(@RequestHeader(value = "customHeader") String customHeader,
@RequestBody(required = false) Product product);
}使用 curl 请求接口并查看日志输出的请求头
curl -X POST http://localhost:8080/api/v1/external/product/add响应错误处理 ErrorDecoder
OpenFeign是一个声明式的Web服务客户端,它使得写HTTP客户端变得更简单,主要用于微服务架构中,以简化服务间的调用。ErrorDecoder是OpenFeign中的一个重要接口,它在处理HTTP响应中的错误时发挥着关键作用。以下是对OpenFeign ErrorDecoder的详细解释:
一、ErrorDecoder的作用
ErrorDecoder接口用于处理HTTP响应中的错误。当OpenFeign客户端发送请求并接收到响应时,如果响应状态码表示错误(如4xx或5xx),则ErrorDecoder会被调用以决定是否将响应视为异常。通过自定义ErrorDecoder,可以对错误进行更精细的处理,比如根据不同的错误码返回不同的异常类型,或者在某些情况下忽略错误。
二、可能使用ErrorDecoder的场景
- 特定错误码处理:根据HTTP响应的不同错误码执行不同的逻辑。
- 忽略某些错误:在某些情况下,可能希望忽略某些特定的错误(如404 Not Found),并返回一个默认值或空对象,而不是抛出异常。
- 增强错误日志:通过自定义ErrorDecoder来增强错误日志,记录更多的上下文信息,以便于调试和监控。
- 统一异常处理:将HTTP错误转换为统一的异常类型,并在应用程序的其他部分进行捕获和处理。
三、自定义ErrorDecoder的步骤
- 创建实现类:创建一个实现ErrorDecoder接口的类。该类需要实现decode方法,该方法接收一个Response对象作为参数,并返回一个Exception对象。在decode方法中,可以根据响应的状态码和其他信息来决定是否将响应视为异常,并返回相应的异常类型。
- 配置Feign客户端:在Feign客户端的配置中指定自定义的ErrorDecoder。这通常是在一个带有@Configuration注解的配置类中,通过@Bean注解来定义一个ErrorDecoder类型的Bean。
四、示例代码
以下是一个自定义ErrorDecoder的示例代码:
import feign.Response;
import feign.codec.DecodeException;
import feign.codec.ErrorDecoder;
import feign.RetryableException;
public class CustomErrorDecoder implements ErrorDecoder {
@Override
public Exception decode(Response response) {
if (response.status() >= 400 && response.status() < 500) {
// 处理客户端错误(如404, 401等)
if (response.status() == 404) {
return new ResourceNotFoundException("Resource not found");
} else if (response.status() == 401) {
return new UnauthorizedException("Unauthorized");
}
// 其他客户端错误可以统一处理或抛出异常
return new DecodeException(response.request().toString(), response);
} else if (response.status() >= 500) {
// 处理服务器错误(如500, 502等)
return new ServerErrorException("Server error");
}
// 对于成功的响应,返回null表示没有错误
return null;
}
// 自定义异常类
public static class ResourceNotFoundException extends RuntimeException {
public ResourceNotFoundException(String message) {
super(message);
}
}
public static class UnauthorizedException extends RuntimeException {
public UnauthorizedException(String message) {
super(message);
}
}
public static class ServerErrorException extends RuntimeException {
public ServerErrorException(String message) {
super(message);
}
}
}然后,在Feign客户端的配置中指定这个自定义的ErrorDecoder:
import org.springframework.cloud.openfeign.EnableFeignClients;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableFeignClients
public class FeignConfig {
@Bean
public ErrorDecoder errorDecoder() {
return new CustomErrorDecoder();
}
}五、注意事项
- 执行顺序:在OpenFeign中,如果同时存在自定义Decoder和ErrorDecoder,当调用服务出现异常时,会先执行ErrorDecoder来处理异常,并将处理结果返回给调用方。如果调用服务正常返回结果,则先执行自定义Decoder对返回结果进行处理。
- 测试与验证:为了测试并验证自定义ErrorDecoder是否正常工作,可以编写单元测试或集成测试来模拟不同的HTTP响应,并检查是否抛出了预期的异常。
通过以上步骤和示例代码,可以灵活地自定义OpenFeign中的ErrorDecoder来处理各种HTTP响应错误。
自定义 ErrorDecoder
/**
* openfeign自定义错误处理
* 问题:在调用feign过程中,需要经常编写代码判断errorCode是否不等于0,是则编写代码抛出业务异常,否则继续执行当前业务代码
* 解决:使用openfeign自定义错误处理后,调用feign不再需要编写代码判断errorCode
*/
public class CustomizeErrorDecoder extends ErrorDecoder.Default {
@Override
public Exception decode(String methodKey, Response response) {
if (response.status() == HttpStatus.BAD_REQUEST.value() ||
response.status() == HttpStatus.FORBIDDEN.value() ||
response.status() == HttpStatus.UNAUTHORIZED.value()) {
String JSON = response.body().toString();
try {
JsonNode node = JSONUtil.ObjectMapperInstance.readTree(JSON);
return new BusinessException(node.get("errorCode").asInt(), node.get("errorMessage").asText());
} catch (IOException ex) {
// 当发生http 400错误时,返回数据不为json格式,则继续使用系统默认处理错误
response = response.toBuilder()
.status(response.status())
.reason(response.reason())
.request(response.request())
.headers(response.headers())
.body(JSON, Util.UTF_8)
.build();
return super.decode(methodKey, response);
}
}
return super.decode(methodKey, response);
}
}注入自定义 ErrorDecoder
// 自定义 OpenFeign 错误解码器
@Bean
ErrorDecoder errorDecoder() {
return new CustomizeErrorDecoder();
}自定义 fallback
todo
分布式事务
微服务架构中为何有分布式事务呢?
微服务架构中存在分布式事务的原因主要与微服务架构的特点和业务需求有关。以下是对此现象的详细解释:
一、微服务架构的特点
- 服务拆分:在微服务架构中,大型应用程序被拆分成多个小型、独立的服务。这些服务通常围绕特定的业务能力或业务领域进行组织,具有高度的内聚性和松散的耦合性。
- 独立部署和管理:每个微服务都可以独立地进行开发、测试和部署,这使得系统的更新和维护变得更加灵活和高效。同时,每个服务也可以有自己的数据库和存储系统。
- 网络通信:微服务之间通过网络进行通信,这增加了系统的复杂性和潜在的故障点。
二、业务需求
- 数据一致性:在微服务架构中,尽管服务被拆分,但某些业务流程可能涉及多个服务的协同工作。例如,一个电商平台的订单处理可能涉及订单服务、库存服务和支付服务等多个服务。为了确保这些服务在处理同一笔业务时数据的一致性,需要使用分布式事务。
- 事务处理:传统的事务处理机制(如ACID事务)通常适用于单个数据库或数据源。但在微服务架构中,由于服务之间使用不同的数据库,传统的事务处理机制无法直接应用。因此,需要一种新的分布式事务处理机制来确保多个服务之间的事务处理的一致性。
三、分布式事务的定义和作用
- 定义:分布式事务是指跨越多个独立数据库或服务的事务,这些服务需要协同工作以确保数据的一致性和完整性。
- 作用:分布式事务的目标是确保所有参与的服务要么全部成功提交,要么全部回滚,以避免数据不一致的问题。这有助于维护系统的数据完整性和可靠性。
四、分布式事务的挑战
- 性能问题:分布式事务通常涉及多个服务之间的通信和协调,增加了网络延迟和资源消耗,从而影响性能。
- 复杂性:实现和管理分布式事务需要复杂的逻辑和协调机制,增加了系统的复杂性。
- 故障恢复:需要处理多种异常情况和失败恢复机制,以确保在出现故障时能够正确地回滚或提交事务。
综上所述,微服务架构中的分布式事务是由于服务拆分、独立部署和管理以及业务需求等多方面因素共同作用的结果。为了确保多个服务之间的事务处理的一致性,需要采用适当的分布式事务处理机制来应对这些挑战。
CAP 定理
详细说明请参考 链接
BASE 理论
BASE理论是对CAP定理的一种补充和扩展,专门用于处理分布式系统中的可用性和一致性问题。以下是关于BASE理论的详细解释:
一、定义与背景
- 定义:BASE理论是“Basically Available,Soft state,Eventual consistency”的缩写,分别代表基本可用、软状态和最终一致性。
- 背景:该理论由eBay的架构师Dan Pritchett提出,源于对大规模互联网分布式系统实践的总结,是对CAP定理的延伸和实际应用补充。CAP定理指出,在分布式系统中无法同时完全实现一致性、可用性和分区容错性,因此需要在三者之间做出权衡。BASE理论则通过牺牲强一致性来提高系统的可用性和容错性。
二、核心要素
- 基本可用(Basically Available)
- 指在出现不可预知的故障时,系统主体功能依然可用。即使在部分系统组件发生故障或网络分区的情况下,系统也能继续运行,只是性能可能会下降,或者某些功能可能暂时不可用。
- 例如,在电商促销时,为保护购物系统,部分消费有可能会被导到一个降级页面。
- 软状态(Soft State)
- 意味着系统中的数据状态可以在一段时间内不一致,并且不要求数据在任意时刻都是一致的。允许系统状态在没有输入的情况下变化。
- 这与ACID事务中的“硬状态”对比鲜明,后者要求数据在事务提交后必须是强一致的。软状态的存在不会影响系统的整体可用性,但要求系统能够在后续操作中通过某种机制使数据达到一致状态。
- 最终一致性(Eventually Consistent)
- 指系统中的所有副本数据在没有新的更新后,将在一段时间内逐渐达到一致。这意味着在不久的将来,所有的读取操作将返回相同的数据,尽管在短期内可能会存在不一致。
- 最终一致性不是实时的,但系统能够确保在合理的时间范围内,所有节点的数据保持一致。这种设计使得系统在保证最终一致性的同时,可以降低同步成本和提高系统性能。
三、应用场景
BASE理论特别适用于那些对可用性要求高但对强一致性要求较低的分布式系统,如:
- NoSQL数据库:如Cassandra、DynamoDB等,采用了BASE理论,通过高可用性和容错性设计,允许数据在短时间内不一致,但最终达到一致性。
- 微服务架构:不同服务之间的数据一致性可以通过异步通信和事件驱动模型实现,允许各服务在短时间内保持软状态,最终达到一致性。
- 缓存系统:如Redis、Memcached等,通过缓存机制提高系统的读写性能,可能会出现数据短暂不一致的情况,但最终会同步到持久化存储中。
四、优势与不足
- 优势:
- 提高了系统的可用性和容错性。
- 降低了同步成本,提高了系统性能。
- 提供了灵活的一致性模型,开发者可以根据实际需求选择合适的一致性策略。
- 不足:
- 由于允许数据在一段时间内处于不一致状态,可能会对用户的使用体验产生一定影响。
- 最终一致性策略需要一定的时间来实现数据的一致状态,这可能会导致一定的延迟,在某些对实时性要求较高的应用场景中可能会产生负面影响。
综上所述,BASE理论为分布式系统的设计提供了一种新的思路和方法,有助于开发者在设计和实现分布式系统时更好地平衡系统的可用性和一致性。
事务 ACID 原则
ACID 原则,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),是数据库事务管理的一组关键属性。这些原则确保了数据库在事务处理过程中的可靠性和完整性。以下是每个原则的详细解释:
- 原子性(Atomicity):
- 原子性是指事务要么全部执行成功,要么全部不执行。事务中的多个操作被视为一个不可分割的单元。
- 如果事务中的某个操作失败,那么事务中的所有操作都必须回滚(撤销),以恢复到事务开始前的状态。
- 一致性(Consistency):
- 一致性确保事务将数据库从一个一致状态转换到另一个一致状态。
- 在事务开始之前和事务结束之后,数据库中的数据必须满足所有的完整性约束和业务规则。
- 这意味着事务不会破坏数据库的完整性,例如,不会违反外键约束、唯一性约束等。
- 隔离性(Isolation):
- 隔离性确保多个事务并发执行时,一个事务的修改在最终提交前对其他事务是不可见的。
- 这样可以避免脏读、不可重复读和幻读等并发问题。
- 隔离级别从低到高包括:未提交读(Read Uncommitted)、提交读(Read Committed)、可重复读(Repeatable Read)和序列化(Serializable)。
- 持久性(Durability):
- 持久性确保一旦事务提交,它对数据库的影响是永久的,即使系统发生故障也不会丢失。
- 这意味着事务的修改被永久地保存在数据库中,即使系统崩溃或重启,这些修改也不会丢失。
ACID 原则对于确保数据库系统的可靠性和完整性至关重要。然而,在某些情况下,为了提高性能和可扩展性,可能会牺牲部分隔离性(例如,使用弱隔离级别),但这通常需要在一致性和性能之间做出权衡。
分布式事务模型
分布式事务模型是指在一个分布式系统中,涉及多个数据库或服务节点的事务处理模型。这些节点可能分布在不同的物理机器或多个不同的系统中,因此保证数据的一致性和完整性变得非常复杂。以下是几种常见的分布式事务模型:
一、两阶段提交(2PC)
- 定义:两阶段提交是一种经典的分布式事务协议,它确保多个参与者在执行事务时能以一致的方式提交或回滚事务。
- 阶段划分:
- 准备阶段:事务协调者向所有参与者发送准备提交的请求,参与者执行本地事务并返回一个“准备好”或“失败”的响应。
- 提交阶段:如果所有参与者都返回了“准备好”,协调者发送“提交”请求,所有参与者提交本地事务;如果有一个或多个参与者返回“失败”,协调者发送“回滚”请求,所有参与者回滚本地事务。
- 优点:强一致性,确保事务要么全部提交,要么全部回滚,保证数据一致性。流程简单,易于理解和实现。
- 缺点:性能问题,参与者需要锁定资源直到提交完成,可能导致长时间锁定,影响系统性能。存在单点故障问题,如果协调者在准备阶段崩溃,系统可能会处于不确定状态。阻塞性,参与者在等待协调者的指令时无法释放锁。
二、三阶段提交(3PC)
- 定义:三阶段提交是对两阶段提交的改进,通过引入超时和预提交机制,减少了阻塞和单点故障的影响。
- 阶段划分:
- CanCommit阶段:协调者向所有参与者发送预提交请求,询问是否可以提交事务。
- PreCommit阶段:参与者执行本地事务,并将准备状态返回给协调者。如果所有参与者都准备就绪,协调者进入下一阶段;否则,发送中止请求。
- DoCommit阶段:协调者根据参与者的确认消息决定是否提交或回滚事务,并通知所有参与者。
- 优点:非阻塞性,引入超时机制后,即使协调者或参与者发生故障,系统也能自动进行超时处理。减少单点故障影响,通过增加CanCommit和PreCommit阶段,系统可以在某些故障情况下自动恢复或采取补救措施。
- 缺点:有性能开销,虽然改善了阻塞问题,但依然需要多次网络交互。
三、TCC(Try-Confirm-Cancel)
- 定义:TCC是一种基于补偿机制的事务管理方式,将每个事务操作分为三步:Try(预留资源)、Confirm(确认提交)、Cancel(取消回滚)。
- 工作原理:在Try阶段,参与者预留资源或进行初步检查;在Confirm阶段,参与者实际执行提交操作;如果Try阶段的某些操作失败,则进入Cancel阶段,执行回滚操作。
- 优点:减少锁定时间,在Try阶段并不真正提交数据,避免了长时间的锁定问题。灵活性强,适用于各种复杂的业务场景。
- 缺点:实现复杂,开发者必须为每个操作定义三步逻辑。适用性有限,某些场景下(如不允许预留资源或无法定义合适的补偿机制)TCC难以应用。
四、Saga
- 定义:Saga模式是一种长事务解决方案,适用于微服务架构中。它将一个长事务拆分为一系列有序的本地事务,每个本地事务都有一个对应的补偿操作。
- 工作原理:如果某个本地事务失败,则调用相应的补偿操作来回滚之前的事务。
- 优点:没有全局锁,不会影响系统性能。提供了较高的灵活性。
- 缺点:事务补偿逻辑需要自行实现,增加了代码复杂度。数据的一致性保障依赖于补偿操作的正确性。
五、基于消息队列的最终一致性
- 定义:通过消息队列实现最终一致性是一种常见的分布式事务解决方案。
- 工作原理:系统将操作拆分为异步消息,确保消息的可靠投递和消费,从而达到事务的最终一致性。
- 优点:异步处理,提高系统的响应能力。适合需要高可用、高性能的场景。
- 缺点:实现最终一致性可能会有短暂的时间窗口不一致。需要处理消息重复、顺序等问题。
综上所述,不同的分布式事务模型各有优缺点,适用于不同的业务场景。在选择分布式事务模型时,需要根据具体业务场景的需求、性能要求以及系统的复杂性来权衡。
Seata
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/demo-spring-cloud-alibaba-seata
介绍
Alibaba Seata(原名Fescar)是一个开源的分布式事务解决方案,旨在解决微服务架构下的事务一致性问题。以下是对Alibaba Seata的详细介绍:
一、核心功能
Alibaba Seata提供了多种事务管理模式,包括AT模式、TCC模式、Saga模式和XA模式,以适应不同业务场景的需求。这些模式各具特点,能够满足从简单到复杂的各种分布式事务处理需求。
二、架构组成
Alibaba Seata的架构主要包括以下几个组成部分:
- 应用程序客户端:负责发起事务请求,并向Seata Server发送事务开始、提交或回滚指令。
- 事务协调器(TC):Seata本身,全局唯一。负责接收来自客户端的事务请求,并协调事务参与者的行为,维护全局事务和分支事务的状态。
- 事务管理器(TM):位于客户端,负责开启和结束全局事务。它定义全局事务的范围,并根据TC维护的全局事务和分支事务状态,做出开启事务、提交事务、回滚事务的决议。
- 资源管理器(RM):位于数据库等资源侧,负责执行具体的分支事务。它管理分支事务上的资源,向TC注册分支事务,并汇报分支事务状态,以及驱动分支事务的提交和回滚。
三、事务模式
- AT模式(Automatic Transaction mode):最常用的模式之一,通过两阶段提交的方式来实现分布式事务。Seata能够自动识别SQL语句,并在事务开始时记录必要的信息(如快照),以便在需要的时候进行回滚。此模式透明性高,对应用来说几乎不需要关心事务的细节;兼容大多数的SQL语句,不需要对现有的SQL进行修改;但可能在第一阶段锁定资源,对性能产生一定影响。
- TCC模式(Try-Confirm-Cancel mode):一种基于业务补偿机制的事务管理模式。它要求业务服务自身实现Try、Confirm和Cancel三个方法,分别对应预留资源、确认预留资源和取消预留资源的操作。此模式允许开发者精确控制每个事务阶段的行为,灵活适应复杂的业务逻辑,但需要开发者自行实现TCC接口,增加了开发工作量。相较于AT模式,TCC模式的性能开销较小,因为它不需要在第一阶段锁定资源。
- Saga模式:一种长事务模式,通过一系列的本地事务来实现最终一致性。Seata会记录每个本地事务的状态,并在必要时触发补偿操作。此模式不保证强一致性,而是通过一系列的补偿动作来达到最终一致性;易于扩展,可以很容易地添加新的事务步骤;补偿操作可以异步执行,减少了阻塞时间。它非常适合业务流程长、需要多个步骤才能完成的场景,以及对最终一致性要求较高但不严格要求即时一致性的场景。
- XA模式:基于两阶段提交协议的分布式事务解决方案,适用于支持XA协议的数据库。
四、使用场景
Alibaba Seata主要适用于以下几种场景:
- 微服务架构下的事务一致性问题:当应用程序被拆分成多个微服务时,单个事务可能跨越多个服务边界。Seata可以确保在这种情况下事务的一致性。
- 协调不同类型的系统:当需要协调数据库、消息队列等不同类型的系统时,Seata提供了一种统一的方式来管理这些系统的事务。
- 多步骤完成的业务流程:对于那些需要多个步骤才能完成的业务流程,Seata的Saga模式可以帮助实现最终一致性。
五、优势特点
- 轻量级框架:对性能的影响较小。
- 多种数据库支持:支持多种主流数据库和中间件,如MySQL、Oracle、RocketMQ等。
- 活跃社区:作为一个开源项目,Seata拥有一个活跃的社区,提供了丰富的文档和支持。
- 高性能:通过优化网络通信和存储机制,提供了高性能的事务处理能力,能够满足大规模分布式系统的需求。
- 易于集成:支持与Spring Cloud、Dubbo、gRPC等主流微服务框架的无缝集成,开发者只需进行简单配置即可使用分布式事务功能。
- 可扩展性:提供了丰富的SPI接口,允许开发者根据具体需求进行扩展和定制,例如自定义事务日志存储、事务协调策略等。
六、应用方式
以在Spring Cloud Alibaba中使用Seata为例,通常包括以下步骤:
- 引入依赖:在项目的pom.xml文件中引入Seata的相关依赖。
- 配置Seata:在application.properties或application.yml文件中配置Seata的相关信息。
- 使用Seata注解:在需要事务支持的服务方法上使用@GlobalTransactional注解。
通过以上步骤,开发者可以轻松地在Spring Cloud Alibaba中使用Seata来管理分布式事务,确保在微服务架构中的数据一致性。
综上所述,Alibaba Seata为分布式事务提供了一个强大的解决方案,它通过多种事务管理模式解决了微服务架构下面临的事务一致性难题。
工作原理
Alibaba Seata的工作原理基于两阶段提交(Two-Phase Commit,2PC)协议,并进行了优化和改进以适应微服务架构的需求。以下是Seata工作原理的详细解释:
一、核心组件
Seata设计了三个主要组件来协调和管理分布式事务:
- 事务协调器(TC,Transaction Coordinator):
- 负责协调全局事务的提交和回滚。
- 管理全局事务的生命周期,跟踪全局事务的状态。
- 在事务的第一阶段接收各分支事务的准备(Prepare)状态,第二阶段根据准备结果决定提交(Commit)或回滚(Rollback)。
- 事务管理器(TM,Transaction Manager):
- 负责启动全局事务,并与TC进行交互。
- 传达事务的开始、提交或回滚指令给TC。
- 资源管理器(RM,Resource Manager):
- 负责管理具体的资源操作,与数据库等资源打交道。
- 执行本地事务的预提交(Prepare)和提交(Commit)或回滚(Rollback)操作。
二、工作原理
Seata的工作流程可以分为两个阶段:准备阶段(Prepare Phase)和提交/回滚阶段(Commit/Rollback Phase)。
- 准备阶段(Prepare Phase):
- 当事务开始时,TM向所有参与的RM发送Prepare请求。
- RM接收到Prepare请求后,会检查本地事务能否成功执行,并预留必要的资源(例如锁定相关行的锁)。
- RM向TM回应Prepare状态(预提交成功或失败)。同时,RM也会向TC注册分支事务,并可能记录SQL执行前后的数据快照(在AT模式下)。
- 提交/回滚阶段(Commit/Rollback Phase):
- 如果所有RM的Prepare请求都成功,TM会向TC发送提交指令,TC随后通知所有RM执行真实的提交操作。
- 如果Prepare请求中有任何失败,或者TM决定回滚事务,TM会向TC发送回滚指令,TC随后通知所有RM执行回滚操作。在回滚过程中,RM会根据之前记录的数据快照(在AT模式下)进行回滚。
三、事务模式
Seata支持多种事务模式,以满足不同业务场景的需求:
- AT模式(Automatic Transaction):
- 基于SQL解析和日志记录实现事务回滚的自动补偿。
- 在第一阶段,Seata会记录SQL执行前后的数据快照。
- 在第二阶段,根据全局事务状态决定提交或利用快照进行回滚。
- TCC模式(Try-Confirm-Cancel):
- 要求业务服务实现Try、Confirm和Cancel三个接口。
- Try阶段预留资源,Confirm阶段确认预留资源并提交,Cancel阶段在失败或回滚时释放预留资源。
- Saga模式:
- 长事务模式,通过一系列本地事务实现最终一致性。
- 每个本地事务都有对应的补偿事务,用于在需要时撤销之前的操作。
- XA模式:
- 基于XA协议实现分布式事务。
- 需要数据库支持XA协议,并遵循两阶段提交协议。
四、其他特性
- 无侵入性:Seata通过AOP(面向切面编程)的方式与业务代码集成,使得在编写业务代码时不需要过多关心事务的细节。
- 支持多种数据库:Seata提供了多种数据库适配器,支持MySQL、Oracle、PostgreSQL等主流关系型数据库。
- 灵活的配置:支持通过配置文件或Nacos等配置中心来动态调整事务的配置。
- 良好的监控能力:提供了监控界面,可以查看全局事务的状态,方便问题的定位和处理。
综上所述,Alibaba Seata通过其独特的设计和工作原理,为微服务架构下的分布式事务管理提供了高效、可靠且易于使用的解决方案。
Docker 运行 Seata
参考文档配置 Docker 运行 Seata 服务
https://seata.apache.org/zh-cn/docs/ops/deploy-by-docker-compose/#nacos%E6%B3%A8%E5%86%8C%E4%B8%AD%E5%BF%83db%E5%AD%98%E5%82%A8
此示例演示 Nacos 注册中心,DB 存储 Seata 服务
application-seata.yaml 配置如下:
server:
port: 7091
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${log.home:${user.home}/logs/seata}
extend:
logstash-appender:
destination: 127.0.0.1:4560
kafka-appender:
bootstrap-servers: 127.0.0.1:9092
topic: logback_to_logstash
console:
user:
username: seata
password: seata
seata:
# Seata 服务数据库链接信息通过本文件配置,不需要使用 Nacos 配置中心配置
#config:
# # support: nacos, consul, apollo, zk, etcd3
# type: nacos
# nacos:
# server-addr: 127.0.0.1:8848
# namespace:
# group: SEATA_GROUP
# username: nacos
# password: nacos
# data-id: seataServer.properties
# Seata 服务注册中心信息配置,Seata 服务在 Nacos 注册名为 seata-server 的服务
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
namespace:
# tc集群名称
cluster: default
username: nacos
password: nacos
context-path:
# Seata 服务使用 MySQL 作为持久化存储,此处配置数据库连接信息
store:
# support: file 、 db 、 redis
mode: db
db:
datasource: druid
dbType: mysql
# 需要根据mysql的版本调整driverClassName
# mysql8及以上版本对应的driver:com.mysql.cj.jdbc.Driver
# mysql8以下版本的driver:com.mysql.jdbc.Driver
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/seata?rewriteBatchedStatements=true
user: root
password: 123456
min-conn: 10
max-conn: 100
global-table: global_table
branch-table: branch_table
lock-table: lock_table
distributed-lock-table: distributed_lock
query-limit: 1000
max-wait: 5000
#server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
ignore:
urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.jpeg,/**/*.ico,/api/v1/auth/login,/metadata/v1/**数据库初始化脚本 db.sql,https://github.com/apache/incubator-seata/blob/develop/script/server/db/mysql.sql
create database if not exists `seata` character set utf8mb4 collate utf8mb4_general_ci;
use `seata`;
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);my-customize.cnf 如下:
[mysqld]
slow_query_log=1
long_query_time=1
slow_query_log_file=slow-query.log
innodb_flush_log_at_trx_commit=0
innodb_file_per_table=1
innodb_buffer_pool_size=4g
# 设置错误信息输出到error.log文件中
# 例如:通过启用innodb_print_all_deadlocks输出的死锁日志
log_error = error.log
# `show engine innodb status\G`命令的`TRANSACTIONS`栏目中会打印当前等待状态的锁对应的表中详细的持有锁信息
innodb_status_output_locks=ON
# 启用binlog
log_bin
# 推荐使用 ROW 格式,但你也可以选择 STATEMENT 或 MIXED
binlog_format = MIXED
# 设置 binlog 文件在自动删除前的保留天数
expire_logs_days = 7
# 设置单个 binlog 文件的最大大小
max_binlog_size = 512M
server-id = 10001docker-compose.yaml 如下:
version: "3.1"
services:
nacos-server:
image: nacos/nacos-server:v2.2.3
environment:
- TZ=Asia/Shanghai
- MODE=standalone
# ports:
# - '8848:8848'
# - '9848:9848'
network_mode: host
db:
image: mysql:8.0.18
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_general_ci
- --skip-character-set-client-handshake
volumes:
- ./db.sql:/docker-entrypoint-initdb.d/db.sql
- ./my-customize.cnf:/etc/mysql/conf.d/my-customize.cnf
environment:
- LANG=C.UTF-8
- TZ=Asia/Shanghai
- MYSQL_ROOT_PASSWORD=123456
# ports:
# - '3306:3306'
network_mode: host
seata-server:
image: seataio/seata-server:2.0.0
# ports:
# - "7091:7091"
# - "8091:8091"
network_mode: host
volumes:
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/localtime" #设置系统时区
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/timezone" #设置时区
- ./application-seata.yml:/seata-server/resources/application.yml
depends_on:
- db
- nacos-server启动 Seata 服务
docker compose up -d登录 Seata 控制台http://127.0.0.1:7091/,帐号:seata,密码:seata
登录 Nacos 控制台http://localhost:8848/,帐号:nacos,密码:nacos,看到 Seata 注册服务名为 seata-server。
AT 模式
使用创建订单,扣减库存,减账户余额演示 AT 模式。
创建订单、库存、账户数据库
create database if not exists seata_order character set utf8mb4 collate utf8mb4_general_ci;
create database if not exists seata_storage character set utf8mb4 collate utf8mb4_general_ci;
create database if not exists seata_account character set utf8mb4 collate utf8mb4_general_ci;分别在 3 个数据库创建 undo_log 日志表(AT 模式需要此数据表,其他模式不需要),https://github.com/apache/incubator-seata/blob/2.x/script/client/at/db/mysql.sql
--
-- Licensed to the Apache Software Foundation (ASF) under one or more
-- contributor license agreements. See the NOTICE file distributed with
-- this work for additional information regarding copyright ownership.
-- The ASF licenses this file to You under the Apache License, Version 2.0
-- (the "License"); you may not use this file except in compliance with
-- the License. You may obtain a copy of the License at
--
-- http://www.apache.org/licenses/LICENSE-2.0
--
-- Unless required by applicable law or agreed to in writing, software
-- distributed under the License is distributed on an "AS IS" BASIS,
-- WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-- See the License for the specific language governing permissions and
-- limitations under the License.
--
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
ALTER TABLE `undo_log` ADD INDEX `ix_log_created` (`log_created`);分别配置 3 个应用都注册到 Nacos 注册中心
分别配置 3 个应用集成到 Seata 服务(注意:seata-spring-boot-starter 版本需要和 Seata 服务器版本对应,否则不能自动回滚事务)
pom 依赖配置如下:
<!-- Seata 依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>application.properties 配置如下:
# Seata 配置
seata.registry.type=nacos
seata.registry.nacos.server-addr=localhost:8848
seata.registry.nacos.namespace=
seata.registry.nacos.group=SEATA_GROUP
seata.registry.nacos.application=seata-server
seata.tx-service-group=default_tx_group
seata.service.vgroup-mapping.default_tx_group=default
seata.data-source-proxy-mode=AT业务方法入口点添加 @GlobalTransaction 注解自动处理异常事务
@GlobalTransactional(name = "order-create", rollbackFor = Exception.class)
public void createOrder(Order order) throws BusinessException {通过注释或者取消注释 AccountService#deduct 方法中的扣款失败失败异常测试事务自动回滚。
请求接口调试
curl -X POST http://localhost:8080/order/create -d 'userId=1&productId=1&count=2&amount=20'TCC 模式
todo
LCN
todo
服务熔断、降级、限流
SpringCloud CircuitBreaker
SpringCloud CircuitBreaker是Spring Cloud提供的一个用于处理分布式系统中服务调用的容错机制。以下是对SpringCloud CircuitBreaker的详细介绍:
一、概述
SpringCloud CircuitBreaker提供了一个跨越不同断路器实现的抽象,允许开发者选择最适合自己应用程序需求的断路器实现。它支持多种断路器实现,如Resilience4j、Hystrix等。其中,Resilience4j是Spring Cloud官方推荐的断路器实现,它是一个轻量级的容错库,专为Java 8及更高版本设计。
二、主要功能
- 熔断:当某个服务的错误率达到一定的阈值时,断路器会迅速切换到打开状态,阻止新的请求继续访问该服务,从而防止系统资源的过度消耗和级联失败的发生。
- 自动恢复:经过一段时间后,断路器会自动从打开状态切换到半开状态,允许部分请求通过以测试服务是否恢复正常。如果测试请求成功,断路器会关闭;否则,会重新打开。
- 监控和报警:SpringCloud CircuitBreaker提供了实时监控和报警功能,可以实时监控断路器的状态、请求成功率、失败率等指标,并在异常情况下发送报警信息。
三、核心组件
- 断路器实例:每个断路器实例都对应一个具体的服务调用。开发者可以通过配置断路器实例的属性来控制熔断器的行为,如失败率阈值、打开状态下的等待时间等。
- 熔断器状态:断路器具有三种普通状态(关闭、打开、半开)和两个特殊状态(禁用和强制打开)。这些状态之间的转换取决于服务的调用情况和配置的策略。
四、配置与使用
- 引入依赖:在项目的pom.xml文件中引入SpringCloud CircuitBreaker的依赖,如Resilience4j的依赖。
- 配置属性:在应用程序的配置文件中配置断路器的属性,如失败率阈值、打开状态下的等待时间、半开状态下允许的最大请求数等。这些配置可以根据实际需求进行调整。
- 使用注解:在需要熔断的服务调用方法上使用
@CircuitBreaker注解,并指定备用方法(fallback)或回退逻辑。当断路器打开时,会调用备用方法或执行回退逻辑。
五、与其他组件的集成
SpringCloud CircuitBreaker可以与Spring Cloud的其他组件进行集成,如Spring Cloud Gateway、Spring Cloud OpenFeign等。通过集成这些组件,可以实现更强大的服务治理和容错能力。
六、注意事项
- 合理设置阈值:在设置失败率阈值时,需要根据服务的实际情况进行合理设置。如果设置得过高,可能会导致服务在正常情况下也被熔断;如果设置得过低,则可能无法有效防止级联失败的发生。
- 监控和报警:建议开启实时监控和报警功能,以便在断路器状态发生变化时及时获取通知并进行处理。
- 定期评估和调整:随着系统的运行和服务的变化,需要定期评估和调整断路器的配置和策略,以确保其始终能够有效地保护系统。
综上所述,SpringCloud CircuitBreaker是一个强大的容错机制,可以帮助开发者在分布式系统中实现服务调用的容错和降级。通过合理配置和使用断路器,可以提高系统的可用性和稳定性,为用户提供更好的服务体验。
Hystrix
注意:feign 客户端调用服务时达到 ribbon.ReadTimeout 超时,即使 execution.isolation.thread.timeoutInMilliseconds 未达到超时时间也会 fallback
配置方式分为 2 种:服务提供者配置服务降级、服务调用者 feign 配置服务降级
注意:进入维护模式,使用 Resilience4J 替代。
Resilience4J
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/demo-spring-cloud-resilience4j
介绍
Resilience4j是一个专为Java应用设计的轻量级容错库,以下是对Resilience4j的详细介绍:
一、简介
Resilience4j受Netflix Hystrix的启发,但专为Java 8和函数式编程而设计。与Hystrix相比,Resilience4j更加轻量级,因为它只使用Vavr库,没有任何其他外部库依赖项。Resilience4j提供了高阶函数(装饰器),以通过断路器、速率限制器、重试或隔板(Bulkhead)增强任何功能接口、lambda表达式或方法引用。此外,Resilience4j可以在任何功能接口、lambda表达式或方法引用上堆叠多个装饰器,且允许开发者选择所需的装饰器。
二、核心组件
Resilience4j提供了丰富的模块化且灵活的容错选项,这些核心组件各自承担不同的职责,能够单独使用或组合使用,以应对不同类型的故障场景。具体组件包括:
- 断路器(Circuit Breaker):当下游服务出现问题时,Resilience4j的断路器可以阻止应用程序持续向故障的服务发送请求,从而提高应用程序的整体可用性。
- 限流器(Rate Limiter):Resilience4j可以防止应用程序向下游服务发送过多的请求,从而防止下游服务过载。限流器通过限制单位时间内允许的请求数量,确保系统在高负载下仍能稳定运行。
- 重试(Retry):在网络不稳定或服务暂时不可用的情况下,Resilience4j可以自动重试失败的操作。
- 隔板(Bulkhead):类似于船舶的舱壁设计,用于将系统划分为多个独立的部分,以防止某个部分的故障影响整个系统。Resilience4j的隔板通过限制并发调用的数量,确保关键资源的可用性。
- 缓存(Cache):用于存储请求的响应结果,减少对后端服务的频繁调用,提高系统的响应速度和可用性。Resilience4j的缓存模块可以与断路器和重试机制结合使用,优化容错策略。
- 时间器(Time Limiter):用于限制调用的最大执行时间,防止长时间阻塞导致系统资源被占用。Resilience4j的时间器通过设置超时时间,当调用超过指定时间后自动中断。
三、特点与优势
- 轻量级且模块化:Resilience4j采用模块化设计,开发者可以根据实际需求选择所需的功能模块,避免引入不必要的依赖,保持项目的轻量性。
- 函数式编程支持:Resilience4j完全基于Java 8的函数式编程理念,能够与现代Java应用无缝集成,提升代码的可读性和可维护性。
- 易于配置和扩展:通过简单的配置文件或代码方式,开发者可以轻松定制各个模块的行为。此外,Resilience4j提供丰富的扩展点,允许用户根据具体需求进行自定义。
- 良好的集成能力:Resilience4j能够与Spring Boot等主流框架良好集成,简化了在现有项目中引入容错机制的过程。同时,它也兼容多种监控工具,方便进行性能监控和故障诊断。
- 活跃的社区和文档支持:Resilience4j拥有活跃的开源社区,提供详尽的文档和丰富的示例,帮助开发者快速上手并解决实际问题。
四、使用场景
Resilience4j主要应用于微服务架构中,提供服务间调用的稳定性和弹性。例如,在一个微服务应用中,可能需要调用一个可能会失败的远程服务。此时,可以使用Resilience4j的熔断器和重试功能来增强服务调用。如果服务调用失败的次数超过了设定的阈值,熔断器就会打开,阻止进一步的服务调用。然后,可以使用重试对象来自动重试失败的服务调用。
五、总结
Resilience4j以其简单易用、灵活配置和良好的性能表现,成为许多Java开发者在构建高可用系统时的首选工具。通过使用Resilience4j,开发者可以更好地应对故障和异常,提高系统的可靠性和可用性。
基本配置
OpenFeign + Resilience4J 组合,OpenFeign 提供远程调用能力,Resilience4J 提供服务熔断和降级能力。SpringBoot 版本 3.3.7 + SpringCloud 版本 2023.0.4 + JDK 版本 17。
pom 添加如下配置:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!-- Resilience4J circuitbreaker 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
<!-- Resilience4J 需要 AOP 支持才能够正常运作 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>application.yaml 配置 circuitbreaker Resilience4J
spring:
cloud:
openfeign:
circuitbreaker:
# 启用 OpenFeign 的断路器功能
enabled: true
# 支持 default 默认配置和指定 feign 的配置
group:
enabled: true
resilience4j:
timelimiter:
configs:
default:
# 设置了超时持续时间为10秒。这意味着,如果一个远程调用的响应时间超过了10秒,它将触发一个超时异常
timeout-duration: 10s
circuitbreaker:
configs:
default:
# 设置了失败率阈值为50%。这意味着,如果在一个滑动窗口时间段内,远程调用的失败率达到了或超过了50%,断路器将会打开,阻止进一步的调用,以保护系统免受进一步的失败影响。
failure-rate-threshold: 50
# 设置了慢调用的持续时间阈值为5秒。这意味着,如果一个远程调用的响应时间超过了5秒,它将被视为一个慢调用。
slow-call-duration-threshold: 1s
# 设置了慢调用率阈值为30%。这意味着,在一个滑动窗口时间段内,如果远程调用的慢调用比率达到了或超过了30%,断路器将会打开。这
slow-call-rate-threshold: 30
# 设置了滑动窗口的类型为基于计数的类型,大小为6。这意味着断路器将使用一个大小为6的计数器来跟踪最近的调用结果。
sliding-window-type: COUNT_BASED
# 设置了滑动窗口的大小为6。这意味着断路器将使用一个大小为6的计数器来跟踪最近的调用结果,以便进行失败率计算和慢调用的统计。
sliding-window-size: 6
# 设置了在断路器打开之前,至少需要6次调用才能触发断路器的状态转换。这意味着,在断路器完全打开之前,必须收集足够的数据来评估系统的健康状况。
minimum-number-of-calls: 6
# 设置了在断路器打开后,自动从开放状态转换到半开状态的标志为true。这意味着,一旦断路器打开,它将尝试在一段时间后重新允许少量的调用通过
automatic-transition-from-open-to-half-open-enabled: true
# 设置了在断路器打开状态下,等待5秒后自动转换到半开状态。这意味着,一旦断路器打开,它将等待5秒钟后再尝试允许少量的调用通过
wait-duration-in-open-state: 5s
# 设置了在断路器半开状态下,允许2次调用通过。这意味着,当断路器从打开状态转换到半开状态时,它将只允许少量的调用尝试执行远程服务的方法
permitted-number-of-calls-in-half-open-state: 2
record-exceptions:
# 指定了在断路器统计失败率时,哪些异常类型应该被记录为失败的调用。这里包括了所有继承自java.lang.Exception的异常类
- java.lang.Exception
# default:
# # 设置了失败率阈值为50%。这意味着,如果在一个滑动窗口时间段内,远程调用的失败率达到了或超过了50%,断路器将会打开,阻止进一步的调用,以保护系统免受进一步的失败影响。
# failure-rate-threshold: 50
# # 设置了慢调用的持续时间阈值为5秒。这意味着,如果一个远程调用的响应时间超过了5秒,它将被视为一个慢调用。
# slow-call-duration-threshold: 1s
# # 设置了慢调用率阈值为30%。这意味着,在一个滑动窗口时间段内,如果远程调用的慢调用比率达到了或超过了30%,断路器将会打开。这
# slow-call-rate-threshold: 30
# # 设置了滑动窗口的类型为基于时间的类型
# sliding-window-type: TIME_BASED
# # 设置了滑动窗口的大小为5。这意味着断路器将使用一个大小为5的时间窗口来跟踪最近的调用结果,以便进行失败率计算和慢调用的统计。
# sliding-window-size: 5
# # 设置了在断路器打开之前,至少需要5次调用才能触发断路器的状态转换。这意味着,在断路器完全打开之前,必须收集足够的数据来评估系统的健康状况。
# minimum-number-of-calls: 5
# # 设置了在断路器打开后,自动从开放状态转换到半开状态的标志为true。这意味着,一旦断路器打开,它将尝试在一段时间后重新允许少量的调用通过
# automatic-transition-from-open-to-half-open-enabled: true
# # 设置了在断路器打开状态下,等待5秒后自动转换到半开状态。这意味着,一旦断路器打开,它将等待5秒钟后再尝试允许少量的调用通过
# wait-duration-in-open-state: 5s
# # 设置了在断路器半开状态下,允许2次调用通过。这意味着,当断路器从打开状态转换到半开状态时,它将只允许少量的调用尝试执行远程服务的方法
# permitted-number-of-calls-in-half-open-state: 2
# record-exceptions:
# # 指定了在断路器统计失败率时,哪些异常类型应该被记录为失败的调用。这里包括了所有继承自java.lang.Exception的异常类
# - java.lang.Exception
instances:
# 指定了名为demo-service-provider的远程服务实例,并使用默认配置(default)来配置断路器参数
demo-service-provider:
base-config: defaultFeign 客户端 FeignClientProvider
@FeignClient(value = "demo-service-provider", path = "/api/v1")
public interface FeignClientProvider {
@GetMapping("test1")
// 配置 Feign 客户端 circuitbreaker resilience4j 服务熔断和降级
@CircuitBreaker(name = "demo-service-provider", fallbackMethod = "test1Fallback")
public ObjectResponse<String> test1(@RequestParam(value = "flag", defaultValue = "") String flag) throws Throwable;
// 服务降级 fallback 方法
default public ObjectResponse<String> test1Fallback(Throwable throwable) {
ObjectResponse<String> response = new ObjectResponse<>();
response.setErrorMessage(throwable.getMessage());
return response;
}
}调用 Feign 客户端
@RestController
@RequestMapping("/api/v1")
public class DemoController {
@Resource
FeignClientProvider feignClientProvider;
@GetMapping("test1")
public ObjectResponse<String> test1(@RequestParam(value = "flag", defaultValue = "") String flag) throws Throwable {
return this.feignClientProvider.test1(flag);
}
}启用 Feign 客户端
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients(clients = {FeignClientProvider.class})
public class ApplicationConsumer {
public static void main(String[] args) {
SpringApplication.run(ApplicationConsumer.class, args);
}
}运行 ApplicationTests#testForCountBased 测试用例
运行示例
注意:运行 ApplicationTests 中不同的测试用例时,在每个测试用例之间需要重启 ApplicationConsumer,否则上次的测试会影响此次的测试。
启动 Consul
docker compose up -d启动 ApplicationProvider、ApplicationConsumer 应用
运行 ApplicationTests#testForCountBased 测试用例
基于计数窗口(CircuitBreaker)
application.yaml 配置如下:
spring:
cloud:
openfeign:
circuitbreaker:
# 启用 OpenFeign 的断路器功能
enabled: true
# 支持 default 默认配置和指定 feign 的配置
group:
enabled: true
resilience4j:
timelimiter:
configs:
default:
# 设置了超时持续时间为10秒。这意味着,如果一个远程调用的响应时间超过了10秒,它将触发一个超时异常
timeout-duration: 10s
circuitbreaker:
configs:
default:
# 设置了失败率阈值为50%。这意味着,如果在一个滑动窗口时间段内,远程调用的失败率达到了或超过了50%,断路器将会打开,阻止进一步的调用,以保护系统免受进一步的失败影响。
failure-rate-threshold: 50
# 设置了慢调用的持续时间阈值为5秒。这意味着,如果一个远程调用的响应时间超过了5秒,它将被视为一个慢调用。
slow-call-duration-threshold: 1s
# 设置了慢调用率阈值为30%。这意味着,在一个滑动窗口时间段内,如果远程调用的慢调用比率达到了或超过了30%,断路器将会打开。这
slow-call-rate-threshold: 30
# 设置了滑动窗口的类型为基于计数的类型,大小为6。这意味着断路器将使用一个大小为6的计数器来跟踪最近的调用结果。
sliding-window-type: COUNT_BASED
# 设置了滑动窗口的大小为6。这意味着断路器将使用一个大小为6的计数器来跟踪最近的调用结果,以便进行失败率计算和慢调用的统计。
sliding-window-size: 6
# 设置了在断路器打开之前,至少需要6次调用才能触发断路器的状态转换。这意味着,在断路器完全打开之前,必须收集足够的数据来评估系统的健康状况。
minimum-number-of-calls: 6
# 设置了在断路器打开后,自动从开放状态转换到半开状态的标志为true。这意味着,一旦断路器打开,它将尝试在一段时间后重新允许少量的调用通过
automatic-transition-from-open-to-half-open-enabled: true
# 设置了在断路器打开状态下,等待5秒后自动转换到半开状态。这意味着,一旦断路器打开,它将等待5秒钟后再尝试允许少量的调用通过
wait-duration-in-open-state: 5s
# 设置了在断路器半开状态下,允许2次调用通过。这意味着,当断路器从打开状态转换到半开状态时,它将只允许少量的调用尝试执行远程服务的方法
permitted-number-of-calls-in-half-open-state: 2
record-exceptions:
# 指定了在断路器统计失败率时,哪些异常类型应该被记录为失败的调用。这里包括了所有继承自java.lang.Exception的异常类
- java.lang.Exception
instances:
# 指定了名为demo-service-provider的远程服务实例,并使用默认配置(default)来配置断路器参数
demo-service-provider:
base-config: defaultFeign 客户端注解 @CircuitBreaker
@FeignClient(value = "demo-service-provider", path = "/api/v1")
public interface FeignClientProvider {
@GetMapping("test1")
// 配置 Feign 客户端 circuitbreaker resilience4j 服务熔断和降级
@CircuitBreaker(name = "demo-service-provider", fallbackMethod = "test1Fallback")
public ObjectResponse<String> test1(@RequestParam(value = "flag", defaultValue = "") String flag) throws Throwable;
// 服务降级 fallback 方法
default public ObjectResponse<String> test1Fallback(Throwable throwable) {
ObjectResponse<String> response = new ObjectResponse<>();
response.setErrorMessage(throwable.getMessage());
return response;
}
}重启 ApplicationConsumer 应用,运行 ApplicationTests#testForCoutBased 测试用例
基于慢调用(CircuitBreaker)
application.yaml 配置如下:
spring:
cloud:
openfeign:
circuitbreaker:
# 启用 OpenFeign 的断路器功能
enabled: true
# 支持 default 默认配置和指定 feign 的配置
group:
enabled: true
resilience4j:
timelimiter:
configs:
default:
# 设置了超时持续时间为10秒。这意味着,如果一个远程调用的响应时间超过了10秒,它将触发一个超时异常
timeout-duration: 10s
circuitbreaker:
configs:
default:
# 设置了慢调用的持续时间阈值为5秒。这意味着,如果一个远程调用的响应时间超过了5秒,它将被视为一个慢调用。
slow-call-duration-threshold: 1s
# 设置了慢调用率阈值为30%。这意味着,在一个滑动窗口时间段内,如果远程调用的慢调用比率达到了或超过了30%,断路器将会打开。这
slow-call-rate-threshold: 30
instances:
# 指定了名为demo-service-provider的远程服务实例,并使用默认配置(default)来配置断路器参数
demo-service-provider:
base-config: defaultFeign 客户端注解 @CircuitBreaker
@FeignClient(value = "demo-service-provider", path = "/api/v1")
public interface FeignClientProvider {
@GetMapping("test1")
// 配置 Feign 客户端 circuitbreaker resilience4j 服务熔断和降级
@CircuitBreaker(name = "demo-service-provider", fallbackMethod = "test1Fallback")
public ObjectResponse<String> test1(@RequestParam(value = "flag", defaultValue = "") String flag) throws Throwable;
// 服务降级 fallback 方法
default public ObjectResponse<String> test1Fallback(Throwable throwable) {
ObjectResponse<String> response = new ObjectResponse<>();
response.setErrorMessage(throwable.getMessage());
return response;
}
}重启 ApplicationConsumer 应用,运行 ApplicationTests#testForSlowCall 测试用例
基于时间窗口(CircuitBreaker)
application.yaml 配置如下:
spring:
cloud:
openfeign:
circuitbreaker:
# 启用 OpenFeign 的断路器功能
enabled: true
# 支持 default 默认配置和指定 feign 的配置
group:
enabled: true
resilience4j:
timelimiter:
configs:
default:
# 设置了超时持续时间为10秒。这意味着,如果一个远程调用的响应时间超过了10秒,它将触发一个超时异常
timeout-duration: 10s
circuitbreaker:
configs:
default:
# 设置了失败率阈值为50%。这意味着,如果在一个滑动窗口时间段内,远程调用的失败率达到了或超过了50%,断路器将会打开,阻止进一步的调用,以保护系统免受进一步的失败影响。
failure-rate-threshold: 50
# 设置了慢调用的持续时间阈值为5秒。这意味着,如果一个远程调用的响应时间超过了5秒,它将被视为一个慢调用。
slow-call-duration-threshold: 1s
# 设置了慢调用率阈值为30%。这意味着,在一个滑动窗口时间段内,如果远程调用的慢调用比率达到了或超过了30%,断路器将会打开。这
slow-call-rate-threshold: 30
# 设置了滑动窗口的类型为基于时间的类型
sliding-window-type: TIME_BASED
# 设置了滑动窗口的大小为5。这意味着断路器将使用一个大小为5的时间窗口来跟踪最近的调用结果,以便进行失败率计算和慢调用的统计。
sliding-window-size: 5
# 设置了在断路器打开之前,至少需要5次调用才能触发断路器的状态转换。这意味着,在断路器完全打开之前,必须收集足够的数据来评估系统的健康状况。
minimum-number-of-calls: 5
# 设置了在断路器打开后,自动从开放状态转换到半开状态的标志为true。这意味着,一旦断路器打开,它将尝试在一段时间后重新允许少量的调用通过
automatic-transition-from-open-to-half-open-enabled: true
# 设置了在断路器打开状态下,等待5秒后自动转换到半开状态。这意味着,一旦断路器打开,它将等待5秒钟后再尝试允许少量的调用通过
wait-duration-in-open-state: 5s
# 设置了在断路器半开状态下,允许2次调用通过。这意味着,当断路器从打开状态转换到半开状态时,它将只允许少量的调用尝试执行远程服务的方法
permitted-number-of-calls-in-half-open-state: 2
record-exceptions:
# 指定了在断路器统计失败率时,哪些异常类型应该被记录为失败的调用。这里包括了所有继承自java.lang.Exception的异常类
- java.lang.Exception
instances:
# 指定了名为demo-service-provider的远程服务实例,并使用默认配置(default)来配置断路器参数
demo-service-provider:
base-config: defaultFeign 客户端注解 @CircuitBreaker
@FeignClient(value = "demo-service-provider", path = "/api/v1")
public interface FeignClientProvider {
@GetMapping("test1")
// 配置 Feign 客户端 circuitbreaker resilience4j 服务熔断和降级
@CircuitBreaker(name = "demo-service-provider", fallbackMethod = "test1Fallback")
public ObjectResponse<String> test1(@RequestParam(value = "flag", defaultValue = "") String flag) throws Throwable;
// 服务降级 fallback 方法
default public ObjectResponse<String> test1Fallback(Throwable throwable) {
ObjectResponse<String> response = new ObjectResponse<>();
response.setErrorMessage(throwable.getMessage());
return response;
}
}重启 ApplicationConsumer 应用,运行 ApplicationTests#testForTimeBased 测试用例
舱壁隔离(Bulkhead)
todo 实验未成功
pom 引入舱壁隔离依赖
<!-- 舱壁隔离(Bulkhead)依赖 -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
</dependency>限流(RateLimiter)
todo 未做实验
Sentinel
详细用法请参考文档 链接
服务链路追踪
微服务链路追踪原理
微服务链路追踪原理主要涉及在分布式系统中跟踪和监控微服务间相互调用的过程。以下是对微服务链路追踪原理的详细解释:
一、链路追踪的定义与背景
链路追踪,全称是Microservices Distributed Tracing,是一种用于监测和诊断分布式应用程序的技术。它允许开发人员跟踪一个请求在分布式系统中的完整路径和流程,从而帮助开发人员和运维团队追踪和诊断分布式系统中的性能问题和故障。
随着微服务架构的流行,服务按照不同的维度进行拆分,在复杂的微服务架构系统中,会形成一个复杂的分布式服务调用链路。由于一次请求往往需要涉及多个服务,每个服务可能是由不同的团队开发,使用了不同的编程语言和框架,因此,如何发现问题、如何追踪服务故障等成为难题。而链路追踪正是为了解决这种问题而诞生的。
二、链路追踪的核心概念
- Trace(追踪):一个完整的请求路径,包括了所有相关的组件和服务。
- Span(跨度):代表请求路径中的一个组件或服务的操作。每个Span都有一个唯一的ID(Span ID),用于标识该操作,同时记录了一些关键的元数据,如开始时间、结束时间、执行耗时等。
- Trace ID(追踪ID):在整个链路中唯一标识一个追踪的ID,可以在各个组件间传递。
- Annotation(注解):用于记录与Span相关的附加信息,如日志、事件、异常等。
- Trace Context(追踪上下文):包含了当前请求的追踪ID、跨度ID等信息,用于在不同组件间传递和关联追踪信息。
三、链路追踪的原理
链路追踪的原理主要是通过在每个组件中插入唯一的标识符(Trace ID)来追踪请求,并将相关信息(如请求的起始时间、耗时、调用链路等)记录下来。这些信息可以帮助开发人员了解整个请求的流程,从而进行故障排除、性能优化和监控分析。
具体来说,当一个请求到达后端后,在处理业务的过程中,可能还会调用其他多个微服务来实现功能。在这个过程中,链路追踪系统会为每个请求生成一个全局唯一的Trace ID,并为这条链路中的每一次分布式调用生成一个Span ID。通过Trace ID和Span ID,系统可以追踪和记录整个请求路径中的每个组件和服务的操作情况。
四、链路追踪的实现方式
目前市面上有多种链路追踪组件可供选择,如Zipkin、Sleuth、Jaeger、Pinpoint等。这些组件都提供了相应的客户端和服务端工具,用于生成、上报、存储、分析和展示追踪数据。
以Zipkin为例,它是一款开源的分布式实时数据追踪系统,能够收集服务间调用的时序数据,提供调用链路的追踪。Zipkin可以分为Zipkin Server和Zipkin Client两部分。Zipkin Server用于数据的采集存储、数据分析与展示;而Zipkin Client则基于不同的语言及框架封装了一系列客户端工具,这些工具完成了追踪数据的生成与上报功能。
五、链路追踪的应用场景
- 故障排查:通过追踪请求的路径和性能指标,可以快速定位和解决故障。
- 性能优化:通过分析请求的性能指标,可以找到系统中的性能瓶颈,并进行优化。
- 依赖分析:通过分析请求的依赖关系,可以了解系统中各个微服务之间的依赖关系,帮助进行系统设计和架构优化。
- 监控和警报:微服务链路追踪可以与监控系统集成,实时监控系统的性能指标,并在达到预设阈值时触发警报。
综上所述,微服务链路追踪原理是通过在每个组件中插入唯一的标识符来追踪请求,并记录相关信息以帮助开发人员了解整个请求的流程。这一技术对于微服务架构中的故障排查、性能优化、依赖分析和监控警报等方面都具有重要意义。
微服务链路追踪时间如何计算
在微服务链路追踪中,时间的计算对于性能分析和故障排查至关重要。以下是如何计算微服务链路追踪中的时间:
一、基本时间参数
- Client Sent(cs):客户端发起调用请求到服务端的时间戳。
- Server Received(sr):服务端接收到了客户端的调用请求的时间戳。
- Server Sent(ss):服务端完成了处理,准备将信息返回给客户端的时间戳。
- Client Received(cr):客户端接收到了服务端的返回信息的时间戳。
二、时间计算方式
- 网络延迟:
- 计算方式:sr - cs
- 含义:表示请求从客户端发送到服务端所花费的时间,即网络传输的延迟。
- 服务执行时间:
- 计算方式:ss - sr
- 含义:表示服务端处理请求所花费的时间,即服务执行的时间。
- 服务响应延迟:
- 计算方式:cr - ss
- 含义:表示服务端完成处理后,将结果返回给客户端所花费的时间,即服务响应的延迟。
- 整个服务调用执行时间:
- 计算方式:cr - cs
- 含义:表示从客户端发起请求到接收到服务端返回结果所花费的总时间,即整个服务调用的执行时间。
三、时间戳的精度
为了确保时间计算的准确性,时间戳通常需要精确到微秒级。这可以通过使用高精度的时间戳生成器或时钟源来实现。
四、实际应用中的考虑
在实际应用中,除了上述基本时间参数外,还需要考虑以下因素:
- 时钟同步:确保所有参与链路追踪的服务节点之间的时钟是同步的,以避免因时钟偏差而导致的时间计算错误。
- 时间记录点:在每个服务节点上,需要选择合适的时间记录点来记录cs、sr、ss和cr等时间戳。这些记录点应该能够准确反映请求在各个阶段的处理情况。
- 数据上传与存储:将记录的时间戳和相关数据上传到链路追踪系统,并进行存储和分析。这有助于开发人员了解系统的性能瓶颈和潜在问题。
综上所述,微服务链路追踪中的时间计算涉及多个时间参数和计算方式。通过准确记录和分析这些时间参数,开发人员可以更好地了解系统的性能表现,并进行针对性的优化和故障排查。
Zipkin
什么是 Zipkin?
Zipkin是一个开源的分布式追踪系统,由Twitter公司开发并贡献给开源社区。它主要用于收集和分析分布式系统中各个服务之间的调用关系及时延数据。以下是关于Zipkin的详细介绍:
一、主要功能
- 分布式追踪:Zipkin能够追踪请求在分布式系统中的传播路径,包括请求经过的所有服务节点以及每个节点上的处理时间。
- 可视化分析:Zipkin提供直观的可视化界面,通过图形化的方式展示请求的调用链路和各个组件的耗时情况,帮助开发人员快速定位性能瓶颈和延迟问题。
- 异常监控:Zipkin能够记录请求中发生的异常情况,并提供异常分析功能,帮助开发人员快速定位和解决问题。
- 依赖分析:Zipkin可以分析系统中各个组件之间的依赖关系,帮助开发人员了解系统的整体架构和组件之间的通信情况。
二、系统架构
Zipkin的系统架构主要包括以下几个部分:
- Collector:Collector是一个收集数据的守护进程,负责接收来自各个服务节点的追踪数据,并进行验证、存储和索引等操作。
- Storage:Storage用于存储追踪数据,默认情况下,Zipkin将数据存储在内存中,但也可以通过配置将其持久化到数据库(如MySQL、ElasticSearch或Cassandra)中。
- Query Service:Query Service是一个返回JSON数据的REST API,用于查询存储在Storage中的追踪数据。
- Web UI:Web UI是Zipkin自带的Web应用程序,通过它可以查询并浏览存储在Storage中的追踪数据,提供直观的可视化界面。
三、工作原理
- 数据收集:在分布式系统中,每个服务节点都需要配置Zipkin客户端(如Brave),用于生成并发送追踪数据到Zipkin服务端。
- 数据传输:追踪数据可以通过多种方式(如HTTP、Kafka或Scribe)传输到Zipkin服务端。
- 数据存储:Collector接收到追踪数据后,会将其存储到指定的存储系统中。
- 数据查询与展示:开发人员可以通过访问Zipkin服务端的Web UI,输入查询条件(如服务名、时间范围等)来搜索追踪数据,并通过可视化界面查看调用链路和各个组件的耗时情况。
四、应用场景
Zipkin广泛应用于微服务架构中,用于监控和调试分布式系统中的服务调用链。通过Zipkin,开发人员可以清晰地看到请求在各个服务节点之间的传播路径和耗时情况,从而快速定位性能瓶颈和延迟问题。此外,Zipkin还可以用于分析系统中各个组件之间的依赖关系,帮助开发人员了解系统的整体架构和组件之间的通信情况。
综上所述,Zipkin是一个功能强大的分布式追踪系统,它能够帮助开发人员监控和调试分布式系统中的服务调用链,提供对系统性能和瓶颈的洞察。通过Zipkin,开发人员可以更加高效地定位和解决性能问题,提升系统的稳定性和响应速度。
使用 Docker 运行 Zipkin
使用 Docker 运行 Zipkin
https://www.jianshu.com/p/60c6fd6a8106、https://www.cnblogs.com/binz/p/12658020.html
运行 Zipkin 服务的 docker-compose.yaml 文件
version: "3.0"
services:
demo-zipkin-server:
image: openzipkin/zipkin
environment:
- TZ=Asia/Shanghai
ports:
- '9411:9411'访问 Zipkin 控制台http://localhost:9411/zipkin/
Sleuth + Zipkin
Tracing in Distributed Systems with Spring Cloud Sleuth
https://reflectoring.io/tracing-with-spring-cloud-sleuth/
注意:逐渐地被 Micrometer Tracing + Zipkin 替代
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-sleuth-parent
运行示例
启动 Zipkin 服务
docker compose up -d启动 ApplicationEureka、ApplicationGateway、ApplicationServiceA、ApplicationServiceB、ApplicationServiceC 应用
访问http://localhost:8080/api/v1/a/test1?name=Dexter创建链路追踪日志记录
访问 Zipkin 控制台http://localhost:9411/zipkin/查看链路追踪日志。
Micrometer Tracing + Zipkin
todo 实验未做完!
Skywalking
详细用法请参考示例 链接
服务网关
netflix zuul(进入维护状态,被springcloud抛弃)、netflix zuul2(推迟上线计划,被springcloud抛弃)、gateway(springcloud自研新一代网关)
Zuul
代理请求到外部服务
详细用法请参考https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-zuul
运行示例步骤如下:
- 先运行
demo-assistant-external-service服务,此服务模拟提供上传和下载的外部服务。 - 再运行
demo-zuul-service服务后,执行其中Tests.java测试。
示例核心配置如下:
zuul网关配置代理外部服务的上传和下载接口,application.yaml配置如下:yamlzuul: routes: # 代理上传和下载接口到外部服务 demo-external-service-api-upload: path: /api/v1/upload url: http://localhost:18090 strip-prefix: false demo-external-service-api-download: path: /api/v1/download/** url: http://localhost:18090 strip-prefix: falsezuul网关自定义filter在请求中注入外部服务的开发者token,代码如下:javapackage com.future.demo.spring.cloud.zuul; import com.netflix.zuul.ZuulFilter; import com.netflix.zuul.context.RequestContext; import javax.servlet.http.HttpServletRequest; import java.util.UUID; public class UploadAndDownloadFilter extends ZuulFilter { @Override public String filterType() { return "pre"; // 在请求被路由之前执行 } @Override public int filterOrder() { return 1; // Filter的执行顺序 } @Override public boolean shouldFilter() { RequestContext ctx = RequestContext.getCurrentContext(); HttpServletRequest request = ctx.getRequest(); // 基于请求URL或其他信息决定是否应用此Filter String requestURI = request.getRequestURI(); // 仅对上传和下载接口应用此filter return requestURI.startsWith("/api/v1/upload") || requestURI.startsWith("/api/v1/download"); } @Override public Object run() { RequestContext ctx = RequestContext.getCurrentContext(); HttpServletRequest request = ctx.getRequest(); // 添加一个名为"token" ctx.addZuulRequestHeader("token", UUID.randomUUID().toString()); return null; } }java@Bean UploadAndDownloadFilter uploadAndDownloadFilter() { return new UploadAndDownloadFilter(); }
路径重写(Path Rewriting)
把 /api/v1/hello 开头的请求路径重写为 /api/v1/a/b/hello 路径
@Component
public class PathRewriteZuulFilter extends ZuulFilter {
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return PreDecorationFilter.FILTER_ORDER + 1;
}
@Override
public boolean shouldFilter() {
RequestContext context = RequestContext.getCurrentContext();
String originalRequestPath = (String) context.get(REQUEST_URI_KEY);
// 只过滤 /api/v1/hello 开始的请求
return originalRequestPath.startsWith("/api/v1/hello");
}
@Override
public Object run() {
RequestContext context = RequestContext.getCurrentContext();
String originalRequestPath = (String) context.get(REQUEST_URI_KEY);
String modifiedRequestPath = "/api/v1/a/b" + originalRequestPath.replace("/api/v1/hello", StringUtils.EMPTY);
context.put(REQUEST_URI_KEY, modifiedRequestPath);
return null;
}
}application.yaml 配置如下:
zuul:
routes:
helloworld:
path: /api/v1/hello/**
service-id: helloworld
strip-prefix: false详细用法请参考本站 示例
Gateway
介绍
SpringCloud Gateway是Spring官方基于Spring 5.0、Spring Boot 2.0和Project Reactor等技术开发的网关,旨在为微服务架构提供简单、有效和统一的API路由管理方式。以下是关于SpringCloud Gateway的详细介绍:
一、主要特性
- 非阻塞式API:
- Spring Cloud Gateway基于WebFlux框架实现,而WebFlux框架底层使用了高性能的Reactor模式通信框架Netty。这种非阻塞式通信方式使得Gateway在高并发场景下具有更好的性能表现。
- 函数式编程端点:
- 通过使用Spring WebFlux的函数式编程模式定义路由端点,处理请求。
- 集成Spring Cloud组件:
- Gateway可以与Eureka、Ribbon、Hystrix等Spring Cloud组件配合使用,实现服务发现、负载均衡、熔断等功能。
- 动态路由:
- 支持根据请求属性匹配对应的路由,并可以基于注册中心的服务发现动态更新路由配置。
- 丰富的过滤器:
- 提供了易于编写的Predicates(断言)和Filters(过滤器),可以作用于特定路由。过滤器可以在请求被路由前或之后对请求进行修改,实现如安全、访问超时设置、限流等横切与应用无关的功能。
二、核心组件
- Route(路由):
- 网关配置的基本组成模块。一个Route模块由一个ID、一个目标URI、一组断言和一组过滤器组成。如果断言为真,则路由匹配,目标URI会被访问。
- Predicate(断言):
- Predicate来自Java 8的接口,可以用来匹配来自HTTP请求的任何内容,例如headers或参数。接口包含多种默认方法,并将Predicate组合成复杂的逻辑(与、或、非),可以用于接口参数校验、路由转发判断等。
- Filter(过滤器):
- 网关过滤器链中的过滤器有两种:GatewayFilter(路由过滤器)和GlobalFilter(全局过滤器)。GatewayFilter作用范围比较灵活,可以是任意指定的路由;而GlobalFilter作用范围是所有路由,不可配置。
三、工作原理
- 请求处理流程:
- 客户端向Spring Cloud Gateway发出HTTP请求。
- Gateway Handler Mapping判断请求与哪个路由匹配。
- 将请求发送到对应的Gateway Web Handler。
- Web Handler加载当前路由下需要执行的过滤器链,并按照顺序逐一执行过滤器。
- 所有过滤器的pre逻辑都依次顺序执行通过后,请求被路由到微服务。
- 微服务返回结果后,再倒序执行过滤器的post逻辑。
- 最终将响应结果返回给客户端。
- 过滤器执行逻辑:
- 在“pre”类型的过滤器中,可以实现参数校验、权限校验、流量监控、日志输出、协议转换等功能。
- 在“post”类型的过滤器中,可以实现响应内容、响应头的修改,日志的输出、流量监控等功能。
四、应用场景
- API路由管理:
- 作为微服务架构的系统统一入口,提供内部服务的路由中转。
- 安全控制:
- 在网关层实现身份验证和授权,确保只有合法的请求才能访问微服务。
- 监控和日志:
- 收集和分析请求数据,为系统的运维和监控提供有力支持。
- 流量控制:
- 限制请求的速率以保护后端服务,防止因过载而导致的服务不可用。
- 熔断和降级:
- 在后端服务不可用时提供默认响应,确保系统的稳定性和可用性。
综上所述,SpringCloud Gateway作为Spring Cloud生态系统中的网关组件,具有高性能、易于集成和丰富的功能特性。它能够为微服务架构提供简单、有效和统一的API路由管理方式,并帮助开发者实现安全控制、监控日志、流量控制等关键功能。
基本配置和示例运行
注意:项目引用 spring-cloud-starter-gateway 依赖后不能同时引用 spring-boot-starter-web 依赖。
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-gateway
父 pom 依赖配置如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2020.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>SpringCloud Gateway 项目 pom 依赖配置如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>SpringCloud Gateway 项目启动类如下:
@SpringBootApplication
public class ApplicationGateway {
public static void main(String[] args) {
SpringApplication.run(ApplicationGateway.class, args);
}
}启动 ApplicationEureka、ApplicationGateway、ApplicationHelloworld 应用
访问http://localhost:8080/提示资源不存在表示 SpringCloud Gateway 配置并启动成功。
路由规则配置
application.properties 配置如下:
# 基本路由规则
spring.cloud.gateway.routes[0].id=test1
# 使用负载均衡算法发送请求到微服务service-helloworld
spring.cloud.gateway.routes[0].uri=lb://service-helloworld
# 使用Path route predicate匹配uri转发路由
spring.cloud.gateway.routes[0].predicates[0]=Path=/api/v1/test1
# 演示同时使用多个predicate
spring.cloud.gateway.routes[1].id=test2
spring.cloud.gateway.routes[1].uri=lb://service-helloworld
# 需要提供param1参数才路由
spring.cloud.gateway.routes[1].predicates[0]=Path=/api/v1/test2
spring.cloud.gateway.routes[1].predicates[1]=Query=param1
# 演示参数等于指定值才路由
spring.cloud.gateway.routes[2].id=test3
spring.cloud.gateway.routes[2].uri=lb://service-helloworld
# 指定param1=h1才路由
spring.cloud.gateway.routes[2].predicates[0]=Path=/api/v1/test3
spring.cloud.gateway.routes[2].predicates[1]=Query=param1,h1
# 演示header等于指定值才路由
spring.cloud.gateway.routes[3].id=test5
spring.cloud.gateway.routes[3].uri=lb://service-helloworld
# 指定header1=h2和header2=h3才路由
spring.cloud.gateway.routes[3].predicates[0]=Path=/api/v1/test5
spring.cloud.gateway.routes[3].predicates[1]=Header=header1,h2
spring.cloud.gateway.routes[3].predicates[2]=Header=header2,h3
# AddRequestHeader、AddRequestParameter filter
spring.cloud.gateway.routes[4].id=test6
spring.cloud.gateway.routes[4].uri=lb://service-helloworld
spring.cloud.gateway.routes[4].predicates[0]=Path=/api/v1/test6
# 自动添加http头 header1=h1
spring.cloud.gateway.routes[4].filters[0]=AddRequestHeader=header1,h1
## 自动删除客户端传入的userId参数,防止注入userId参数
spring.cloud.gateway.routes[4].filters[1]=RemoveRequestParameter=userId
# 自动添加http参数 userId=2
spring.cloud.gateway.routes[4].filters[2]=AddRequestParameter=userId,2
spring.cloud.gateway.routes[5].id=router-service-helloworld-oss-getObject
spring.cloud.gateway.routes[5].uri=lb://service-helloworld
spring.cloud.gateway.routes[5].predicates[0]=Path=/obs-*/**
# filter My会自动查找 MyGatewayFilterFactory,即自定义局部filter命名规则为XxxGatewayFilterFactory
spring.cloud.gateway.routes[5].filters[0]=My
spring.cloud.gateway.routes[5].filters[1]=AddRequestHeader=header1,hvalue1
spring.cloud.gateway.routes[5].filters[2]=AddRequestParameter=param1,pvalue1谓词(Predicate)
Path
# 基本路由规则
spring.cloud.gateway.routes[0].id=test1
# 使用负载均衡算法发送请求到微服务service-helloworld
spring.cloud.gateway.routes[0].uri=lb://service-helloworld
# 使用Path route predicate匹配uri转发路由
spring.cloud.gateway.routes[0].predicates[0]=Path=/api/v1/test1spring.cloud.gateway.routes[5].id=router-service-helloworld-oss-getObject
spring.cloud.gateway.routes[5].uri=lb://service-helloworld
spring.cloud.gateway.routes[5].predicates[0]=Path=/obs-*/**
# filter My会自动查找 MyGatewayFilterFactory,即自定义局部filter命名规则为XxxGatewayFilterFactory
spring.cloud.gateway.routes[5].filters[0]=My
spring.cloud.gateway.routes[5].filters[1]=AddRequestHeader=header1,hvalue1
spring.cloud.gateway.routes[5].filters[2]=AddRequestParameter=param1,pvalue1Query
# 演示同时使用多个predicate
spring.cloud.gateway.routes[1].id=test2
spring.cloud.gateway.routes[1].uri=lb://service-helloworld
# 需要提供param1参数才路由
spring.cloud.gateway.routes[1].predicates[0]=Path=/api/v1/test2
spring.cloud.gateway.routes[1].predicates[1]=Query=param1# 演示参数等于指定值才路由
spring.cloud.gateway.routes[2].id=test3
spring.cloud.gateway.routes[2].uri=lb://service-helloworld
# 指定param1=h1才路由
spring.cloud.gateway.routes[2].predicates[0]=Path=/api/v1/test3
spring.cloud.gateway.routes[2].predicates[1]=Query=param1,h1Header
# 演示header等于指定值才路由
spring.cloud.gateway.routes[3].id=test5
spring.cloud.gateway.routes[3].uri=lb://service-helloworld
# 指定header1=h2和header2=h3才路由
spring.cloud.gateway.routes[3].predicates[0]=Path=/api/v1/test5
spring.cloud.gateway.routes[3].predicates[1]=Header=header1,h2
spring.cloud.gateway.routes[3].predicates[2]=Header=header2,h3过滤器(Filter)
注意:predicate 不通过是不会调用 filter(包括全局、局部 filter)的
内置 Filter
AddRequestHeader
# AddRequestHeader、AddRequestParameter filter
spring.cloud.gateway.routes[4].id=test6
spring.cloud.gateway.routes[4].uri=lb://service-helloworld
spring.cloud.gateway.routes[4].predicates[0]=Path=/api/v1/test6
# 自动添加http头 header1=h1
spring.cloud.gateway.routes[4].filters[0]=AddRequestHeader=header1,h1
## 自动删除客户端传入的userId参数,防止注入userId参数
spring.cloud.gateway.routes[4].filters[1]=RemoveRequestParameter=userId
# 自动添加http参数 userId=2
spring.cloud.gateway.routes[4].filters[2]=AddRequestParameter=userId,2AddRequestParameter
# AddRequestHeader、AddRequestParameter filter
spring.cloud.gateway.routes[4].id=test6
spring.cloud.gateway.routes[4].uri=lb://service-helloworld
spring.cloud.gateway.routes[4].predicates[0]=Path=/api/v1/test6
# 自动添加http头 header1=h1
spring.cloud.gateway.routes[4].filters[0]=AddRequestHeader=header1,h1
## 自动删除客户端传入的userId参数,防止注入userId参数
spring.cloud.gateway.routes[4].filters[1]=RemoveRequestParameter=userId
# 自动添加http参数 userId=2
spring.cloud.gateway.routes[4].filters[2]=AddRequestParameter=userId,2RemoveRequestParameter
# AddRequestHeader、AddRequestParameter filter
spring.cloud.gateway.routes[4].id=test6
spring.cloud.gateway.routes[4].uri=lb://service-helloworld
spring.cloud.gateway.routes[4].predicates[0]=Path=/api/v1/test6
# 自动添加http头 header1=h1
spring.cloud.gateway.routes[4].filters[0]=AddRequestHeader=header1,h1
## 自动删除客户端传入的userId参数,防止注入userId参数
spring.cloud.gateway.routes[4].filters[1]=RemoveRequestParameter=userId
# 自动添加http参数 userId=2
spring.cloud.gateway.routes[4].filters[2]=AddRequestParameter=userId,2全局 Filter
使用 GlobalFilter 定义全局 filter
每种全局
Filter在 gateway 中只会有一个实例,会对所有的Route都生效。自定义GlobalFilter作为权限验证
https://www.pianshen.com/article/4176276100/、https://www.cnblogs.com/h--d/p/12741935.html
MyGlobalFilter
@Slf4j
@Component
public class MyGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String uri = exchange.getRequest().getURI().getPath();
log.debug("请求前uri={},params={}", uri, exchange.getRequest().getQueryParams());
Mono<Void> mono = chain.filter(exchange);
log.debug("请求后response={}", exchange.getResponse());
return mono;
}
@Override
public int getOrder() {
return 0;
}
}使用全局 Filter 之需要注解其为 @Component 即可
局部 Filter
使用 AbstractGatewayFilterFactory 定义局部 filter
路由
Filter是针对Route进行配置的,不同的Route可以使用不同的参数,因此会创建不同的实例。注意:自定义局部 filter 命名规则为 XxxGatewayFilterFactory
MyGatewayFilterFactory
@Slf4j
@Component
public class MyGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {
final static ObjectMapper OBJECT_MAPPER = new ObjectMapper();
@Override
public GatewayFilter apply(Object config) {
return (exchange, chain) -> {
ServerHttpRequest request = exchange.getRequest();
String originalUri = request.getURI().getPath();
String uri = originalUri.substring(1);
String[] uriParts = uri.split("/", 2);
if(uriParts.length<2) {
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.BAD_REQUEST);
response.getHeaders().setContentType(MediaType.APPLICATION_JSON);
final String errMsg = "请求路径 " + originalUri + " 错误,例如: http://localhost:8080/obs-default-epu-555-33/2021-08-20/uuu-01.jpg" ;
return response.writeWith(Mono.create(monoSink -> {
try {
Map<String, Object> errorResponseMap = new HashMap<>();
errorResponseMap.put("errorCode", 600);
errorResponseMap.put("errorMessage", errMsg);
String responseJSON = OBJECT_MAPPER.writeValueAsString(errorResponseMap);
DataBuffer dataBuffer = response.bufferFactory().wrap(responseJSON.getBytes(StandardCharsets.UTF_8));
monoSink.success(dataBuffer);
}
catch (Exception ex) {
log.error("对象输出异常", ex);
monoSink.error(ex);
}
}));
}
String bucketName = uriParts[0];
String objectName = uriParts[1];
String obsPrefix = "obs-";
bucketName = bucketName.substring(obsPrefix.length());
try {
objectName = URLEncoder.encode(objectName, StandardCharsets.UTF_8.name());
} catch (UnsupportedEncodingException e) {
log.error(e.getMessage(), e);
}
log.debug("bucketName=" + bucketName + ",objectName=" + objectName);
request = request.mutate()
.uri(URI.create("/api/v1/oss/getObject"))
.header("bucketName", bucketName)
.header("objectName", objectName)
.build();
return chain.filter(exchange.mutate().request(request).build());
};
}
}使用 Filter
spring.cloud.gateway.routes[5].id=router-service-helloworld-oss-getObject
spring.cloud.gateway.routes[5].uri=lb://service-helloworld
spring.cloud.gateway.routes[5].predicates[0]=Path=/obs-*/**
# filter My会自动查找 MyGatewayFilterFactory,即自定义局部filter命名规则为XxxGatewayFilterFactory
spring.cloud.gateway.routes[5].filters[0]=My
spring.cloud.gateway.routes[5].filters[1]=AddRequestHeader=header1,hvalue1
spring.cloud.gateway.routes[5].filters[2]=AddRequestParameter=param1,pvalue1和 Spring Security 集成
todo 未做实验
服务配置和管理
定义
微服务服务配置和管理是微服务架构中的关键环节,它涉及到服务的启动、运行、性能、安全性和可扩展性等多个方面。以下是对微服务服务配置和管理的详细阐述:
一、微服务配置管理的概念
微服务配置管理是指在微服务架构中对各个服务的配置数据进行统一管理和控制的过程。这些配置数据包括但不限于数据库连接信息、API密钥、环境变量、服务端口、日志级别等。有效的配置管理能够确保服务在不同环境中的一致性,并快速响应业务需求变化。
二、微服务配置管理的策略
- 外部化配置:将应用程序的配置文件从代码中分离,使其能独立于应用程序进行管理。这种策略允许开发人员在不修改代码的情况下更改配置,提升了配置的灵活性和可管理性。
- 动态配置:支持在运行时修改配置,而无需重启服务。这能够根据业务需求实时调整配置,提高系统响应速度和可用性,同时降低运维成本。
- 版本控制与审计:对配置文件进行版本控制,可以追踪任何更改并回滚到以前的版本。同时,确保所有配置变更都有记录,便于审计和排查问题。
三、微服务配置管理的最佳实践
- 使用环境变量:对于敏感信息(如数据库密码),建议使用环境变量存储,避免将其硬编码在配置文件中。这不仅提高了安全性,也使得配置更加灵活。
- 采用加密机制:确保敏感配置项(如API密钥)采用加密存储,防止配置被未授权访问。可以使用专门的加密工具或服务进行管理。
- 定期审计配置:定期检查和审计配置变更,确保没有未授权的访问或更改。可以利用工具对配置历史进行保存和审核,增强系统的安全性。
- 选择合适的配置管理工具:常用的配置管理工具有Spring Cloud Config、Apollo、Disconf等,它们提供了集中化的配置管理服务,支持多种配置源和动态更新。选择适合团队和项目的工具,可以提高配置管理的效率和效果。
- 结合CI/CD工具实现自动化部署:结合持续集成和持续部署(CI/CD)工具,实现配置的自动化部署和更新。这可以显著降低配置管理的复杂性,提高部署的效率和可靠性。
四、微服务配置管理的挑战与解决方案
- 挑战:随着微服务数量的增加和复杂度的提升,配置管理的难度也会增加。如何确保所有服务的配置数据一致、准确和安全成为了一个重要的问题。
- 解决方案:
- 建立统一的配置管理平台和规范,确保所有服务都遵循相同的配置管理策略。
- 引入自动化工具和流程,减少人为错误和重复劳动。
- 定期对配置数据进行审计和检查,及时发现和解决问题。
综上所述,微服务服务配置和管理是微服务架构中不可或缺的一部分。通过外部化配置、动态更新、版本控制与审计等策略以及最佳实践的应用,可以确保服务在不同环境中的一致性、安全性和可扩展性。同时,选择合适的配置管理工具和结合CI/CD工具实现自动化部署也是提高配置管理效率和效果的关键。
Config + Bus
注意:Nacos 逐渐替代 Config + Bus,所以不做实验。
SpringCloud Config Server
使用 Consul 或者 Nacos 替代,很久之前已经做过实验
https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-config-center。
Consul
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-consul-parent
基本配置
访问 Consul http://localhost:8500/ 按照约定添加 yaml 配置
profile=default 时 yaml 配置 config/spring-cloud-service-c/data(config 是约定的目录前缀,spring-cloud-service-c 是微服务名称,data 是约定的配置文件名称)
yamlmy: k1: default,version=1profile=dev 时 yaml 配置 config/spring-cloud-service-c-dev/data(config 是约定的目录前缀,spring-cloud-service-c 是微服务名称,-dev 是 dev profile,data 是约定的配置文件名称)
yamlmy: k1: dev,version=1profile=prod 时 yaml 配置 config/spring-cloud-service-c-prod/data(config 是约定的目录前缀,spring-cloud-service-c 是微服务名称,-prod 是 prod profile,data 是约定的配置文件名称)
yamlmy: k1: prod,version=1
pom 添加 Consul 配置客户端依赖
<!-- Consul 作为服务配置和管理服务器的依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
</dependency>bootstrap.yml 内容如下:
spring:
application:
name: spring-cloud-service-c
cloud:
consul:
host: 127.0.0.1
port: 8500
discovery:
service-name: ${spring.application.name}
# 配置 Consul 作为服务配置和管理服务器
config:
# Consul 不同 profile 配置目录路径使用 '-' 分隔,
# 例如: config/spring-cloud-service-c-dev/data、config/spring-cloud-service-c-prod/data
profile-separator: '-'
format: YAML
# 5 从 Consul 刷新一次配置
watch:
wait-time: 5
# 加载 Consul 配置中心的 config/spring-cloud-service-c-prod/data 目录下的配置文件
profiles:
active: prodapplication.yml 内容如下:
server:
port: 8083使用 @Value 注入配置 my.k1
@RestController
// 自定从 Consul 配置中心刷新到最新配置
@RefreshScope
public class ApiController {
@Value("${my.k1:}")
private String k1;
/**
* @param name
* @return
*/
@RequestMapping(value = "/api/v1/c/sayHello", method = RequestMethod.POST)
public String sayHello(@RequestParam(value = "name", defaultValue = "") String name) {
return "Hello " + name + "!!!,配置k1=" + k1;
}
}访问http://localhost:8081/api/v1/a/sayHello?name=Dexter查看是否成功加载 my.k1 配置。
@RefreshScope 自动刷新配置
在 @Value 所在类添加 @RefreshScope 自动刷新配置
// 自定从 Consul 配置中心刷新到最新配置
@RefreshScope
public class ApiController {
@Value("${my.k1:}")
private String k1;Nacos
详细用法请参考文档 链接
SpringCloud Alibaba
https://spring-cloud-alibaba-group.github.io/github-pages/hoxton/zh-cn/index.html
Nacos
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-nacos
Docker 运行 Nacos
https://blog.csdn.net/qq_27615455/article/details/125168548Docker 运行 nacos2.x 需要暴露 9848 和 9849 端口
https://github.com/alibaba/nacos/issues/6154
docker-compose.yaml 内容如下:
version: "3.0"
services:
# https://blog.csdn.net/qq_27615455/article/details/125168548
# docker运行nacos2.x需要暴露9848和9849端口
# https://github.com/alibaba/nacos/issues/6154
demo-spring-cloud-nacos-server:
image: nacos/nacos-server:v2.2.0
environment:
- TZ=Asia/Shanghai
- MODE=standalone
#- PREFER_HOST_MODE=hostname
ports:
- '8848:8848'
- '9848:9848'
#- '9849:9849'启动 Nacos
docker compose up -d访问http://localhost:8848/nacos登录 Nacos 控制台,帐号:nacos,密码:nacos。
运行示例
运行 Nacos
docker compose up -d手动在 Nacos 配置中心中创建配置文件 demo-springcloud-helloworld-dev.properties,内容为 my.config=v1
手动在 Nacos 配置中心创建 ns_dev 命名空间,在 ns_dev 命名空间下创建 demo-springcloud-zuul-dev.properties 文件,内容为 my.config=ns_dev,DEV_GROUP,demo-springcloud-zuul-dev.properties,Group 为 DEV_GROUP
启动 ApplicationZuul、ApplicationHelloworld 应用
测试服务注册和发现
- 访问
http://localhost:8080/api/v1/zuul/test1?param1=dexter
测试服务配置
- 访问
http://localhost:8080/api/v1/zuul/test1?param1=dexter查看当前 myConfig 返回值为 v1 - 访问 Nacos 控制台手动修改 demo-springcloud-helloworld-dev.properties 内容为 my.config=v2
- 再次访问
http://localhost:8080/api/v1/zuul/test1?param1=dexter查看当前 myConfig 返回值为 v2
测试服务配置 Group、Namespace
- 访问
http://localhost:8080/api/v1/zuul/test2测试
服务注册和发现配置
父 pom 配置如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.7.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- nacos依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.9.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>各个微服务项目的 pom 配置如下:
<!-- nacos注册中心依赖配置 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>application.properties 配置服务注册与发现
# nacos注册中心配置
spring.cloud.nacos.discovery.server-addr=localhost:8848访问http://localhost:8848/nacos Nacos 控制台查看已注册服务
定义 HelloworldClient Feign 客户端
@FeignClient(value = "demo-springcloud-helloworld")
public interface HelloworldClient {
@GetMapping(value = "/api/v1/test1")
ResponseEntity<String> test1(@RequestParam(value = "param1") String param1);
}调用 Feign 客户端
@RestController
@RequestMapping("/api/v1/zuul")
@RefreshScope
public class ApiController {
@Autowired
HelloworldClient helloworldClient;
@GetMapping(value = "test1")
public ResponseEntity<String> test1(@RequestParam(value = "param1", defaultValue = "") String param1) {
return helloworldClient.test1(param1);
}
}服务配置和管理
基本配置
父 pom 配置如下:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.7.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- nacos依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.9.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>各个微服务项目的 pom 配置如下:
<!-- nacos服务配置依赖配置 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>bootstrap.properties 配置如下:
# nacos服务配置设置
# 手动在nacos创建配置文件demo-springcloud-helloworld-dev.properties,内容为:my.config=v1
spring.cloud.nacos.config.server-addr=localhost:8848
spring.cloud.nacos.config.file-extension=properties
spring.profiles.active=devJava 中引用 properties 配置
@RestController
// nacos配置修改后会自动刷新
@RefreshScope
public class ApiController {
@Value("${server.port}")
private int serverPort;
@Value("${my.config}")
private String myConfig;
@GetMapping(value = "/api/v1/test1")
public ResponseEntity<String> test1(@RequestParam(value = "param1", defaultValue = "") String param1) {
return ResponseEntity.ok("你的请求参数param1=" + param1 + ",myConfig配置值:" + myConfig + ",端口: " + serverPort);
}
}自动刷新配置
在引用配置的类中添加 @RefreshScope 注解
@RestController
// nacos配置修改后会自动刷新
@RefreshScope
public class ApiController {
@Value("${server.port}")
private int serverPort;
@Value("${my.config}")
private String myConfig;
@GetMapping(value = "/api/v1/test1")
public ResponseEntity<String> test1(@RequestParam(value = "param1", defaultValue = "") String param1) {
return ResponseEntity.ok("你的请求参数param1=" + param1 + ",myConfig配置值:" + myConfig + ",端口: " + serverPort);
}
}Nacos DataId 和配置文件的命名规则
默认情况:${spring.application.name}-${spring.profiles.active}.$
指定配置:${spring.cloud.nacos.config.prefix}-${spring.profiles.active}.$
根据 Namespace、Group、DataId 加载配置
在Nacos配置管理系统中,Namespace、Group和DataId是三个至关重要的概念。以下是对这三个概念的详细解释:
Namespace
Namespace在Nacos中主要用于进行配置隔离。不同的命名空间下,可以存在相同的Group或DataId的配置。Namespace的常用场景之一是不同环境的配置的区分隔离,例如开发测试环境和生产环境的资源(如配置、服务)隔离等。通过Namespace,我们可以轻松实现不同开发环境的配置隔离,确保各个环境的配置互不干扰。
Group
Group在Nacos中主要用于区分不同的微服务或应用组件。当不同的应用或组件使用了相同的配置类型时,我们可以利用Group来区分它们。例如,一个应用可能使用了database_url配置和MQ_topic配置,我们可以将这些配置分别划分到不同的Group中,以便更好地管理和维护。默认情况下,所有的配置集都属于DEFAULT_GROUP,但用户可以根据需要创建自定义的分组。
Group在Nacos中的作用主要包括:
- 配置隔离:通过分组,可以将不同项目或不同环境的配置进行隔离,避免配置之间的冲突。
- 逻辑区分:对于同名但属于不同项目或不同环境的配置,可以通过分组进行区分,提高配置的可读性和可维护性。
- 权限管理:在一些场景下,可以通过分组进行权限控制,限制不同用户对配置集的访问和操作。
DataId
DataId是Nacos中用于唯一标识配置信息的标识符。每个DataId对应一个具体的配置信息,例如一个数据库连接信息或消息队列的配置。通过DataId,我们可以轻松地查找、获取和更新配置信息。
DataId在Nacos中的主要作用包括:
- 唯一标识配置文件:在Nacos中,每个配置文件通过DataId进行唯一标识。
- 区分不同业务模块的配置:通过自定义DataId格式,可以将配置文件与具体业务模块关联,从而更方便地管理和查找配置。
在实际应用中,DataId的设计通常遵循以下原则:
- 描述性强:DataId应能直观地描述配置的用途、所属模块和环境。
- 可扩展性好:避免在DataId中使用绝对路径或硬编码的命名方式,确保未来能够根据业务变化灵活扩展。
- 避免歧义:DataId应尽量避免使用相似或容易混淆的命名方式。
三者之间的关系
在Nacos中,Namespace、Group和DataId三者之间可以看作是一个层次结构。最外层的Namespace用于区分不同的开发环境或部署环境,它提供了配置隔离的功能。Group位于Namespace之下,用于区分不同的微服务或应用组件。而DataId则位于最内层,用于唯一标识具体的配置信息。
通过合理地设置Namespace、Group和DataId,我们可以实现配置信息的有效管理和维护。例如,我们可以为每个环境创建一个独立的Namespace,然后在每个Namespace下为每个微服务或应用组件创建一个Group,最后在Group下为每个配置信息创建一个唯一的DataId。这样,我们就可以轻松地管理和维护各个环境的配置信息,确保系统的正常运行。
总的来说,Namespace、Group和DataId是Nacos配置管理系统的核心要素。理解这三者的关系并正确应用它们,是实现高效配置管理的关键。
bootstrap.properties 配置如下:
# 演示DataId、Group、Namespace用法
# NOTE: 以下配置只能在bootstrap.properties中配置,否则不生效
spring.cloud.nacos.config.server-addr=localhost:8848
# 加载 properties 配置文件
spring.cloud.nacos.config.file-extension=properties
# 配置文件所在的命令空间为 ns_dev
spring.cloud.nacos.config.namespace=ns_dev
# 配置文件所在的 Group 为 DEV_GROUP
spring.cloud.nacos.config.group=DEV_GROUP
spring.profiles.active=dev手动在 Nacos 配置中心创建 ns_dev 命名空间,在 ns_dev 命名空间下创建 demo-springcloud-zuul-dev.properties 文件,内容为 my.config=ns_dev,DEV_GROUP,demo-springcloud-zuul-dev.properties,Group 为 DEV_GROUP
Sentinel
SpringCloud Alibaba 配置 Sentinel 官方文档
https://spring-cloud-alibaba-group.github.io/github-pages/hoxton/zh-cn/index.html
详细用法请参考示例https://gitee.com/dexterleslie/demonstration/tree/master/spring-cloud/spring-cloud-sentinel
介绍
Alibaba Sentinel是阿里巴巴开源的一款面向分布式微服务架构的轻量级高可用流量控制组件。以下是对Alibaba Sentinel的详细介绍:
一、诞生与发展
- 2012年,Sentinel诞生于阿里巴巴,其主要目标是流量控制。
- 2013~2017年,Sentinel迅速发展,并成为阿里巴巴所有微服务的基本组成部分。它已在6000多个应用程序中使用,涵盖了几乎所有核心电子商务场景。
- 2018年,Sentinel演变为一个开源项目。
- 2020年,Sentinel Golang发布。
二、主要功能
Sentinel以流量为切入点,从多个维度帮助用户保护服务的稳定性,其主要功能包括:
- 流量控制:Sentinel可以监控和控制服务的流量,防止突发流量导致系统崩溃。它支持多种流控模式,如直接流控、关联流控、链路流控等,可以根据实际场景灵活选择。
- 熔断降级:当调用链路中的某个资源出现不稳定状态时(如调用超时或异常比例升高),Sentinel可以对该资源的调用进行限制,让请求快速失败,避免影响到其它资源而导致级联错误。
- 系统负载保护:Sentinel可以监控系统的负载情况,当系统负载过高时,自动触发保护策略,防止系统崩溃。
三、应用场景
Sentinel承接了阿里巴巴近10年的双十一大促流量的核心场景,如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
四、主要特性
- 丰富的实时监控:Sentinel提供实时的监控功能,可以在控制台中看到接入应用的单台机器秒级数据,甚至500台以下规模的集群的汇总运行情况。
- 广泛的开源生态:Sentinel提供开箱即用的与其它开源框架/库的整合模块,例如与Spring Cloud、Apache Dubbo、gRPC、Quarkus等的整合。用户只需要引入相应的依赖并进行简单的配置即可快速地接入Sentinel。
- 完善的SPI扩展机制:Sentinel提供简单易用、完善的SPI扩展接口,用户可以通过实现扩展接口来快速地定制逻辑,如定制规则管理、适配动态数据源等。
五、核心组件
- 核心库(Java客户端):不依赖任何框架/库,能够运行于所有Java运行时环境,同时对Dubbo/Spring Cloud等框架也有较好的支持。
- 控制台(Dashboard):基于Spring Boot开发,打包后可以直接运行,不需要额外的Tomcat等应用容器。控制台主要负责管理推送规则、监控、集群限流分配管理、机器发现等。
六、使用与配置
- 用户可以从Sentinel的官方GitHub页面下载最新版本的控制台jar包,或者使用源码构建。
- 启动控制台后,用户可以通过浏览器访问控制台页面,并使用默认的用户名和密码(均为sentinel,从1.6.0版本起支持自定义)进行登录。
- 在项目中引入Sentinel,需要在项目的pom文件中添加相应的依赖,并在配置文件中进行简单的配置。
- 用户可以通过Sentinel提供的API来定义一个资源,使其能够被Sentinel保护起来。通常情况下,可以使用方法名、URL甚至是服务名来作为资源名来描述某个资源。
- Sentinel支持多种规则配置,如流量控制规则、熔断降级规则等,这些规则都可以在控制台中进行动态调整。
总的来说,Alibaba Sentinel是一款功能强大、易于使用且生态广泛的微服务流量控制组件,它能够帮助用户有效地保护服务的稳定性并提高系统的可用性。
Docker 运行 Sentinel
注意:Sentinel 没有官方的 Docker 镜像,目前实验使用的非官方镜像为 bladex/sentinel-dashboard:1.7.0,事实上可以自己编译 Sentinel Docker 镜像。
docker-compose.yaml 配置如下:
version: "3.0"
services:
demo-spring-cloud-sentinel:
image: bladex/sentinel-dashboard:1.8.0
environment:
- TZ=Asia/Shanghai
ports:
- '8858:8858'启动 Sentinel 服务
docker compose up -d访问 Sentinel 控制台http://localhost:8858/,帐号:sentinel,密码:sentinel
和 SpringCloud Alibaba 集成的配置
父 pom 依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.7.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- SpringCloud Alibaba 依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.9.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>各个微服务 pom Sentinel 依赖配置
<!-- sentinel依赖配置 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>各个微服务 application.properties 配置
# sentinel配置
spring.cloud.sentinel.transport.dashboard=localhost:8858运行示例
启动 Sentinel 服务
docker compose up -d启动 ApplicationGateway、ApplicationHelloworld 应用
访问http://localhost:8080/api/v1/test1产生 Sentinel 测试数据
访问http://localhost:8858/ Sentinel 控制台查看测试数据
流控规则
介绍
Sentinel是一个开源的系统保护和流量控制组件,主要设计用于保护微服务架构中的服务。它提供了丰富的流量控制和熔断机制,通过流量控制规则来限制系统的访问频率和并发量,从而确保服务的稳定性和可用性。以下是对Sentinel流控规则的详细介绍:
一、流控规则的基本属性
流控规则主要由以下几个关键属性组成:
- 资源名:唯一名称,默认请求路径,是限流规则的作用对象。
- 针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认为default(不区分来源)。
- 阈值类型/单机阈值:包括QPS(每秒钟的请求数量)和并发线程数。当调用该API的QPS或并发线程数达到阈值时,会触发限流。
- 流控模式:
- 直接:API达到限流条件时,直接限流。
- 关联:当关联的资源达到阈值时,限流自己。
- 链路:只记录指定链路上的流量,指定资源从入口资源进来的流量如果达到阈值,则进行限流。这类似于针对来源的配置项,但区别在于链路流控是针对上级接口,粒度更细。
- 流控效果:
- 快速失败:直接失败,抛异常。
- Warm Up:根据冷加载因子(codeFactor,默认3)的值,从阈值/codeFactor开始,经过预热时长后,逐渐达到设置的QPS阈值。这种方式适用于流量突然增加时,给系统一个预热的时间,避免系统被压垮。
- 排队等待:匀速排队,让请求以匀速的速度通过。这种方式适用于处理间隔性突发的流量,例如消息队列。但需要注意的是,匀速排队模式暂时不支持QPS大于1000的场景。阈值类型必须设置为QPS,否则无效。
二、流控规则的具体应用
- QPS限流:通过设定QPS阈值来控制接口的访问频率。例如,单机阈值设定为1,表示当前这个接口1秒只能被访问一次,超过这个阈值就会被Sentinel阻塞。
- 并发线程数限流:通过设定并发线程数阈值来控制同时访问接口的线程数量。例如,阈值设置为5,表示同时进入到此方法的线程最多有5个,超过5个的线程都会被拒绝。
- 关联流控:当A接口关联的资源B达到阈值后,就限流A接口本身。这种方式适用于需要保护关键资源或接口的场景。
- 链路流控:当从某个接口过来的资源达到限流条件时,开启限流。这种方式适用于需要从整体上控制应用入口流量的场景。
- Warm Up流控:通过冷启动方式,让流量缓慢增加,在一定时间内逐渐增加到阈值上限。这种方式适用于防止秒杀瞬间造成系统崩溃的场景。
- 匀速排队流控:严格控制请求通过的间隔时间,让请求以均匀的速度通过。这种方式适用于处理间隔性突发的流量场景。
三、流控规则的配置方式
流控规则可以通过Sentinel控制台进行配置和管理。开发者可以根据实际需求,灵活地组合使用不同的流控规则和效果,以实现更加复杂的流量控制策略。
综上所述,Sentinel的流控规则为微服务架构中的服务提供了强大的流量控制和保护能力。通过合理配置流控规则,可以有效地避免系统被突发的流量高峰冲垮,从而保障应用的高可用性和稳定性。
流控模式 - 直接
API 达到限流条件时,直接限流。
访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
/api/v1/test1 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流控模式为
直接 - 流控效果为
快速失败
点击新增按钮新增流控规则,1 秒内连续访问http://localhost:8080/api/v1/test1会报告Blocked by Sentinel: FlowException错误。
流控模式 - 关联
当关联的资源达到阈值时,限流自己。
访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
/api/v1/test1 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流控模式为
关联 - 关联资源为
/api/v1/test2 - 流控效果为
快速失败
点击新增按钮新增流控规则(表示资源/api/v1/test2达到阈值时资源/api/v1/test1限流)。
启动 JMeter 给资源/api/v1/test2压力,此时请求资源/api/v1/test1会被限流并报告Blocked by Sentinel: FlowException错误。
流控模式 - 链路
只记录指定链路上的流量,指定资源从入口资源进来的流量如果达到阈值,则进行限流。这类似于针对来源的配置项,但区别在于链路流控是针对上级接口,粒度更细。
application.properties 添加如下配置:
# 当spring.cloud.sentinel.web-context-unify设置为false时,Sentinel会区分每一个具体的URL路径,
# 每个不同的URL都会被视为一个独立的资源。这提供了更细粒度的控制,允许开发者为每一个具体的URL路径定义不同的流控、熔断等规则。
spring.cloud.sentinel.web-context-unify=false通过资源/api/v1/test1和/api/v2/test2调用资源common1
@RestController
@RequestMapping("/api/v1")
public class ApiController {
@Resource
CommonService commonService;
@GetMapping(value = "test1")
public ResponseEntity<String> test1() {
this.commonService.test1();
return ResponseEntity.ok("/api/v1/test1 " + UUID.randomUUID());
}
@GetMapping(value = "test2")
public ResponseEntity<String> test2() {
this.commonService.test1();
return ResponseEntity.ok("/api/v1/test2 " + UUID.randomUUID());
}
}@Service
public class CommonService {
@SentinelResource(value="common1")
public void test1() {
}
}访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
common1 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流控模式为
链路 - 入口资源为
/api/v1/test1 - 流控效果为
快速失败
点击新增按钮新增流控规则(表示通过资源/api/v1/test1调用资源common1限流,通过资源/api/v1/test2调用资源common1不限流)。
访问http://localhost:8080/api/v1/test1限流,访问http://localhost:8080/api/v1/test2不限流。
流控效果 - 快速失败
直接失败,抛 FlowException 异常。
访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
/api/v1/test1 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流量模式为
直接 - 流控效果为
快速失败
点击新增按钮新增流控规则。
访问http://localhost:8080/api/v1/test1限流报告Blocked by Sentinel (flow limiting)错误。
流控效果 - Warm Up
根据冷加载因子(codeFactor,默认3)的值,从阈值/codeFactor开始,经过预热时长后,逐渐达到设置的QPS阈值。这种方式适用于流量突然增加时,给系统一个预热的时间,避免系统被压垮。
访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
/api/v1/test1 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
10 - 是否集群为
不勾选 - 流量模式为
直接 - 流控效果为
Warm Up - 预热时长为
10秒
点击新增按钮新增流控规则。
访问http://localhost:8080/api/v1/test1,前 10 秒会单机阈值为 10/3 = 3.3 QPS(连续请求 /api/v1/test1 会报告限流错误),10 秒后单机阈值恢复为 10 QPS(连续请求 /api/v1/test1 不会报告限流错误,因为阈值恢复为 10 QPS)。
流控效果 - 排队等待
匀速排队,让请求以匀速的速度通过。这种方式适用于处理间隔性突发的流量,例如消息队列。但需要注意的是,匀速排队模式暂时不支持QPS大于1000的场景。阈值类型必须设置为QPS,否则无效。
访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
/api/v1/test1 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流量模式为
直接 - 流控效果为
排队等待 - 超时时间为
10000毫秒
点击新增按钮新增流控规则。
使用 JMeter 创建线程数为 20,0 秒启动完毕,循环 1 次,请求http://localhost:8080/api/v1/test1。有 11 个请求以 1 QPS 速率被处理,9 个请求被拒绝(因为超时时间为10000毫秒,阈值为1 QPS)。
阈值类型 - 线程数
通过设定并发线程数阈值来控制同时访问接口的线程数量。例如,阈值设置为5,表示同时进入到此方法的线程最多有5个,超过5个的线程都会被拒绝。
访问http://localhost:8858/#/dashboard/flow/demo-springcloud-gateway新增流控规则,流控规则信息如下:
- 资源名为
/api/v1/test1 - 针对来源为
default - 阈值类型为
线程数 - 单机阈值为
1 - 是否集群为
不勾选 - 流量模式为
直接
点击新增按钮新增流控规则。
使用 JMeter 创建线程数为 20,0 秒启动完毕,无限循环,请求http://localhost:8080/api/v1/test1。在 JMeter 压力测试过程中访问http://localhost:8080/api/v1/test1因为没有足够的线程处理请求所以会被限流。
熔断规则
介绍
Sentinel是一款面向分布式服务架构的轻量级流量控制组件,主要通过流量控制、熔断降级和系统自适应保护等手段,确保服务的稳定性和可用性。在Sentinel中,熔断机制是一种重要的保护策略,它类似于电路中的熔断器,能够在服务出现故障或负载过高时切断请求,从而防止系统崩溃。以下是关于Sentinel熔断规则的详细介绍:
一、熔断机制的工作原理
熔断机制的工作原理通常包括以下几个步骤:
- 监控服务:持续监控服务的健康状态和负载情况。
- 触发熔断:当服务出现故障(如响应时间过长、异常比例过高等)或负载过高时,触发熔断机制。
- 熔断动作:执行熔断动作,例如拒绝新的请求、调用降级策略等,以保护系统免受进一步影响。
- 恢复服务:在一段时间后(即熔断时长结束后),尝试恢复服务,并根据恢复情况决定是否继续熔断。此时服务会进入半开状态(HALF-OPEN状态),允许一定量的请求通过以测试服务是否已恢复。如果请求成功,则关闭熔断器;如果请求失败,则再次触发熔断。
二、常见的熔断规则类型
Sentinel提供了多种熔断规则类型,以适应不同的业务场景和需求。以下是几种常见的熔断规则:
- 慢调用比例(SLOW_REQUEST_RATIO):
- 定义:选择以慢调用比例作为阈值,需要设置允许的慢调用RT(即最大的响应时间)。请求的响应时间大于该值则统计为慢调用。
- 触发条件:当单位统计时长内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值时,触发熔断。
- 恢复条件:经过熔断时长后,服务进入半开状态。若接下来的一个请求响应时间小于设置的慢调用RT,则结束熔断;否则,会再次被熔断。
- 异常比例(ERROR_RATIO):
- 定义:当单位统计时长内请求数目大于设置的最小请求数目,并且异常的比例大于阈值时,触发熔断。
- 触发条件:异常比率的阈值范围是[0.0, 1.0],代表0%至100%。
- 恢复条件:经过熔断时长后,服务进入半开状态。若接下来的一个请求成功完成(没有错误),则结束熔断;否则,会再次被熔断。
- 异常数(ERROR_COUNT):
- 定义:当单位统计时长内的异常数目超过阈值时,触发熔断。
- 触发条件:无需考虑请求数目和异常比例,只需异常数目超过设定阈值。
- 恢复条件:经过熔断时长后,服务进入半开状态。若接下来的一个请求成功完成(没有错误),则结束熔断;否则,会再次被熔断。
三、熔断规则的配置与应用
在Sentinel中,熔断规则可以通过配置文件或动态配置中心进行设置。配置完成后,Sentinel将自动根据这些规则对流量进行控制和降级操作。同时,Sentinel还提供了实时监控功能,可以实时查看系统的运行状态和各项指标,便于问题排查和规则优化。
此外,为了获得最佳效果,用户需要根据实际业务场景和系统特点进行合理的规则配置和优化工作。例如,可以根据服务的响应时间、异常比例、请求量等指标来设置合适的熔断阈值,以确保服务在高并发和故障场景下仍能保持良好的运行状态。
综上所述,Sentinel的熔断规则是保护分布式服务架构稳定性和可用性的重要手段。通过合理配置和应用这些规则,用户可以有效地防止系统因流量过大或故障而崩溃,从而提高服务的稳定性和可用性。
慢调用比例
访问http://localhost:8858/#/dashboard/degrade/demo-springcloud-gateway新增规则,规则信息如下:
- 资源名为
/api/v1/test1 - 熔断策略为
慢调用比例 - 最大 RT 为
1000毫秒(超过 1 秒的接口被认为慢调用) - 比例阈值为
0.5(慢调用比例超过 50% 触发熔断) - 熔断时长为
10秒(熔断持续时间为 10 秒,之后自动切换为半开状态) - 最小请求数
5(最小请求数为 5 次才触发熔断机制) - 统计时长
2000毫秒(统计时间窗口为 2 秒)
使用 JMeter 创建线程数为 10,0 秒启动完毕,无限循环,请求http://localhost:8080/api/v1/test1?sleepInSeconds=3。在 JMeter 压力测试过程中访问http://localhost:8080/api/v1/test1熔断报告错误。
异常比例
访问http://localhost:8858/#/dashboard/degrade/demo-springcloud-gateway新增规则,规则信息如下:
- 资源名为
/api/v1/test2 - 熔断策略为
异常比例 - 比例阈值为
0.5(比例超过 50% 触发熔断) - 熔断时长为
10秒(熔断持续时间为 10 秒,之后自动切换为半开状态) - 最小请求数
5(最小请求数为 5 次才触发熔断机制) - 统计时长
2000毫秒(统计时间窗口为 2 秒)
使用 JMeter 创建线程数为 10,0 秒启动完毕,无限循环,请求http://localhost:8080/api/v1/test2?flag=exception。在 JMeter 压力测试过程中访问http://localhost:8080/api/v1/test2熔断报告错误。
异常数
访问http://localhost:8858/#/dashboard/degrade/demo-springcloud-gateway新增规则,规则信息如下:
- 资源名为
/api/v1/test2 - 熔断策略为
异常数 - 异常数
3(异常数量超过 3 触发熔断) - 熔断时长为
10秒(熔断持续时间为 10 秒,之后自动切换为半开状态) - 最小请求数
5(最小请求数为 5 次才触发熔断机制) - 统计时长
2000毫秒(统计时间窗口为 2 秒)
使用 JMeter 创建线程数为 10,0 秒启动完毕,无限循环,请求http://localhost:8080/api/v1/test2?flag=exception。在 JMeter 压力测试过程中访问http://localhost:8080/api/v1/test2熔断报告错误。
@SentinelResource 注解
介绍
@SentinelResource 是 Alibaba Sentinel 提供的一个注解,用于定义资源,并可以与 Sentinel 的流控、降级等规则进行关联。通过该注解,开发者可以非常方便地在代码中对某些方法进行保护,防止在高并发或异常情况下导致系统崩溃。
以下是 @SentinelResource 注解的一些关键属性和用法:
关键属性
- value:资源的唯一标识名称。这个名称用于在 Sentinel 控制台配置规则。如果不指定,则默认为方法的全限定名(类名+方法名)。
- entryType:指定资源的入口类型。可选值有
EntryType.IN(表示普通入口,默认值)和EntryType.OUT(表示异步出口)。 - blockHandler:指定处理被限流或被降级逻辑的处理器方法名。该方法必须与原方法在同一个类中,且返回类型、方法参数列表(除了第一个参数类型为
BlockException)需要与原方法一致。 - fallback:指定默认的降级返回值。当方法被限流、降级、系统异常时,会直接返回该值。注意,
fallback和blockHandler是互斥的,不能同时使用。 - defaultFallback:指定类级别的默认降级返回值。当方法被限流、降级、系统异常时,如果该方法没有定义
fallback,则会使用这个类级别的默认降级值。defaultFallback需要定义在类上。 - exceptionsToIgnore:指定哪些异常类型会被忽略,不进行降级处理。
使用示例
基本使用
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
public class MyService {
@SentinelResource(value = "myMethod", fallback = "defaultFallback")
public String myMethod() {
// 业务逻辑
return "Hello, Sentinel!";
}
public String defaultFallback() {
return "Fallback response for myMethod";
}
}在这个例子中,如果 myMethod 被限流或降级,将会调用 defaultFallback 方法。
使用 blockHandler
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
public class MyService {
@SentinelResource(value = "myMethod", blockHandler = "handleBlock")
public String myMethod() {
// 业务逻辑
return "Hello, Sentinel!";
}
public String handleBlock(BlockException ex) {
// 处理被限流的逻辑
return "Blocked by Sentinel: " + ex.getMessage();
}
}在这个例子中,如果 myMethod 被限流,将会调用 handleBlock 方法来处理限流逻辑。
注意事项
blockHandler和fallback方法的参数列表必须与原方法一致(除了blockHandler方法第一个参数是BlockException类型)。- 如果使用了
blockHandler或fallback方法,需要确保这些方法在同一个类中定义。 SentinelResource注解主要用于对单个方法的保护,对于更复杂的场景,可以考虑使用 Sentinel 的编程 API 来定义资源。
通过使用 @SentinelResource 注解,开发者可以非常方便地在代码中集成 Sentinel 的流量控制和降级功能,提高系统的稳定性和可用性。
自定义资源名称限流
@GetMapping(value = "test3")
@SentinelResource(value = "test3")
public ResponseEntity<String> test3() {
return ResponseEntity.ok("/api/v1/test3 " + UUID.randomUUID());
}流控规则信息:
- 资源名为
test3 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流控模式为
直接 - 流控效果为
快速失败
请求http://localhost:8080/api/v1/test3测试自定义资源名称限流效果。
自定义限流返回 blockHandler
blockHandler 是在流量控制触发时调用
@GetMapping(value = "test3")
@SentinelResource(value = "test3", blockHandler = "blockHandler")
public ObjectResponse<String> test3() {
ObjectResponse<String> response = new ObjectResponse<>();
response.setData("/api/v1/test3 " + UUID.randomUUID());
return response;
}
public ObjectResponse<String> blockHandler(BlockException ex) {
ObjectResponse<String> response = new ObjectResponse<>();
response.setData("被限流降级了");
return response;
}流控规则信息:
- 资源名为
test3 - 针对来源为
default - 阈值类型为
QPS - 单机阈值为
1 - 是否集群为
不勾选 - 流控模式为
直接 - 流控效果为
快速失败
请求http://localhost:8080/api/v1/test3测试效果。
自定义服务降级 fallback
fallback 是在熔断降级触发时调用
@GetMapping(value = "test3")
@SentinelResource(value = "test3", fallback = "fallback")
public ObjectResponse<String> test3(@RequestParam(value = "flag", defaultValue = "") String flag) {
if ("exception".equals(flag)) {
throw new RuntimeException("预期异常");
}
ObjectResponse<String> response = new ObjectResponse<>();
response.setData("/api/v1/test3 " + UUID.randomUUID());
return response;
}
public ObjectResponse<String> fallback(@RequestParam(value = "flag", defaultValue = "") String flag, Throwable ex) {
ObjectResponse<String> response = new ObjectResponse<>();
response.setData("服务降级了");
return response;
}熔断规则信息:
- 资源名为
test3 - 熔断策略为
异常比例 - 比例阈值为
0.5 - 熔断时长为
10秒 - 最小请求数为
5 - 统计时长为
1000毫秒
使用 JMeter 创建线程数为 10,0 秒启动完毕,无限循环,请求http://localhost:8080/api/v1/test3?flag=exception。在 JMeter 压力测试过程中访问http://localhost:8080/api/v1/test3熔断报告错误。
blockHandler 和 fallback 区别
在微服务架构中,Sentinel 是一个非常流行的开源流量控制、熔断降级组件,由阿里巴巴开源。它主要用于服务的稳定性保障,确保在高并发、系统不稳定等场景下,服务不会崩溃,并能够在必要时进行降级处理。在 Sentinel 中,@SentinelResource 注解是一个关键的工具,用于对方法调用进行流量控制和熔断降级处理。
@SentinelResource 注解提供了两个重要的属性:blockHandler 和 fallback,它们用于定义在特定条件下调用的降级逻辑。
blockHandler
blockHandler 用于处理流量控制(如 QPS 超出限制)的情况。当方法的调用被 Sentinel 流量控制规则拦截时,会调用 blockHandler 指定的方法。
- 使用方式:
blockHandler属性值应该是一个方法名,该方法需要在同一个类中定义,并且方法签名要与原方法一致,或者多一个BlockException类型的参数。 - 返回值:
blockHandler方法的返回值类型必须与原方法一致。
@SentinelResource(value = "exampleMethod", blockHandler = "blockHandlerMethod")
public String exampleMethod() {
// 原始业务逻辑
return "Hello, Sentinel!";
}
public String blockHandlerMethod(BlockException ex) {
// 降级处理逻辑
return "Blocked by Sentinel!";
}fallback
fallback 用于处理熔断降级的情况,比如服务调用失败、异常抛出等。当方法的调用被 Sentinel 熔断规则拦截时,会调用 fallback 指定的方法。
- 使用方式:
fallback属性值也应该是一个方法名,该方法需要在同一个类中定义,并且方法签名要与原方法一致,或者多一个Throwable类型的参数(用于接收原始方法抛出的异常)。 - 返回值:
fallback方法的返回值类型必须与原方法一致。
@SentinelResource(value = "exampleMethod", fallback = "fallbackMethod")
public String exampleMethod() {
// 原始业务逻辑
return "Hello, Sentinel!";
}
public String fallbackMethod(Throwable ex) {
// 降级处理逻辑
return "Fallback by Sentinel!";
}区别与选择
- 触发条件:
blockHandler是在流量控制触发时调用,而fallback是在熔断降级触发时调用。 - 参数:
blockHandler方法多一个BlockException参数,fallback方法多一个Throwable参数。 - 使用场景:根据实际需求选择使用哪个属性。如果需要处理流量控制的情况,使用
blockHandler;如果需要处理服务异常或熔断的情况,使用fallback。
注意事项
blockHandler和fallback方法必须定义在同一个类中,并且不能是静态方法。- 方法签名需要匹配或增加一个特定的异常参数。
- 返回值类型必须与原方法一致。
通过合理使用 @SentinelResource 注解的 blockHandler 和 fallback 属性,可以大大提高微服务系统的稳定性和可靠性。
热点规则
介绍
Sentinel热点规则主要用于对热点参数进行流量控制,以保护系统免受突发高流量的冲击。以下是对Sentinel热点规则的详细介绍:
一、热点参数限流概述
热点参数限流是一种特殊的流量控制策略,它针对的是那些经常被访问的热点数据。通过统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。这种策略可以有效地防止某些热点数据被过度访问,从而保护系统的稳定性和可用性。
二、热点规则配置
在Sentinel中,热点规则的配置通常包括以下几个关键要素:
- 资源名称:需要限流的资源名称,通常与接口路径或方法名称相对应。
- 热点参数索引:指定要进行限流的热点参数在请求参数中的位置(从0开始计数)。
- 限流阈值:在指定时间窗口内,允许该热点参数被访问的最大次数。一旦超过这个阈值,就会触发限流策略。
- 限流模式:Sentinel支持多种限流模式,如直接失败、预热模式、排队等待等。不同的限流模式适用于不同的场景和需求。
三、热点规则示例
假设有一个电商系统,需要对商品ID进行热点参数限流。以下是一个简单的示例:
- 配置热点规则:
- 资源名称:
getProductById - 热点参数索引:0(假设商品ID是请求的第一个参数)
- 限流阈值:10(每秒允许访问10次)
- 限流模式:直接失败(超过阈值后直接返回限流提示)
- 资源名称:
- 代码示例:
@RestController
public class ProductController {
@GetMapping("/product/{id}")
@SentinelResource(value = "getProductById", blockHandler = "handleBlock")
public Product getProductById(@PathVariable("id") String productId) {
// 查询商品信息的逻辑
return new Product(productId, "商品名称", "商品描述", 100.0);
}
public Product handleBlock(String productId, BlockException ex) {
// 限流处理逻辑,如返回默认商品信息或提示用户稍后再试
return new Product("defaultId", "默认商品", "默认描述", 0.0);
}
}在上述代码中,@SentinelResource注解用于定义资源,并指定了限流处理的方法handleBlock。当请求的商品ID超过限流阈值时,会触发handleBlock方法,返回默认的商品信息或提示用户稍后再试。
四、热点参数例外项
Sentinel还支持热点参数例外项的配置,允许对特定的热点参数值设置不同的限流阈值。例如,对于某些热门商品,可以设置更高的访问阈值以满足用户的正常需求。
五、注意事项
- 参数类型支持:Sentinel热点规则支持多种参数类型,但具体支持哪些类型取决于Sentinel的版本和配置。
- 性能影响:热点参数限流会对系统性能产生一定的影响,特别是在高并发场景下。因此,在配置热点规则时,需要权衡限流效果和性能开销。
- 规则持久化:为了确保热点规则在重启后仍然有效,建议将规则持久化到数据库或配置中心等持久化存储中。
综上所述,Sentinel热点规则是一种有效的流量控制策略,可以帮助开发者保护系统免受突发高流量的冲击。通过合理配置热点规则,可以确保系统的稳定性和可用性。
基本使用
@GetMapping(value = "test3")
@SentinelResource(value = "test3")
public ObjectResponse<String> test3(@RequestParam(value = "flag", required = false) String flag,
@RequestParam(value = "p2", required = false) String p2) {
if ("exception".equals(flag)) {
throw new RuntimeException("预期异常");
}
ObjectResponse<String> response = new ObjectResponse<>();
response.setData("/api/v1/test3 " + UUID.randomUUID());
return response;
}热点规则信息:
- 资源名为
test3 - 限流模式为
QPS模式 - 参数索引为
0(表示带第一个参数的请求被限流) - 单机阈值为
1 - 统计窗口时长为
1秒 - 是否集群为
不勾选
带参数 flag 的请求被限流http://localhost:8080/api/v1/test3?flag=1,不带参数的 flag 的请求不会被限流http://localhost:8080/api/v1/test3?p2=1
参数例外项
@GetMapping(value = "test3")
@SentinelResource(value = "test3")
public ObjectResponse<String> test3(@RequestParam(value = "flag", required = false) String flag,
@RequestParam(value = "p2", required = false) String p2) {
if ("exception".equals(flag)) {
throw new RuntimeException("预期异常");
}
ObjectResponse<String> response = new ObjectResponse<>();
response.setData("/api/v1/test3 " + UUID.randomUUID());
return response;
}热点规则信息:
- 资源名为
test3 - 限流模式为
QPS模式 - 参数索引为
0(表示带第一个参数的请求被限流) - 单机阈值为
1 - 统计窗口时长为
1秒 - 是否集群为
不勾选 - 参数例外项的参数类型为
java.lang.String - 参数例外项的参数值为
2 - 参数例外项的限流阈值为
200
参数 flag=1 的请求被限流为1 QPS http://localhost:8080/api/v1/test3?flag=1,参数 flag=2 的请求被限流为200 QPS http://localhost:8080/api/v1/test3?flag=2
授权规则
介绍
Sentinel的授权规则是一种用于控制服务调用方来源的访问控制机制。以下是关于Sentinel授权规则的详细介绍:
一、基本概念
- 授权规则:用于对请求方的来源进行判断和控制,决定是否允许访问受保护的资源。
- 白名单:只有来源在白名单内的调用者才允许访问资源。
- 黑名单:来源在黑名单内的调用者不允许访问资源,其余来源的调用者则可以访问。
二、如何获取请求来源(origin)
Sentinel通过RequestOriginParser接口的parseOrigin方法来获取请求的来源。默认情况下,Sentinel不管请求者从哪里来,返回值都是"default",即所有请求的来源都被认为是一样的值"default"。因此,需要自定义这个接口的实现,让不同的请求返回不同的origin。
自定义RequestOriginParser接口的实现类时,可以从请求的Header中获取某个参数来标明调用方的身份,例如从请求的Header中获取"origin"字段或"source"字段的值作为调用方的身份标识。
三、配置授权规则
在Sentinel控制台中,可以新增授权规则,配置受保护的资源、调用方名单(origin)以及授权类型(白名单或黑名单)。
- 资源名:受保护的资源,例如
/order/query。 - 流控应用:调用方名单(origin),可以配置多个来源,用逗号分隔。
- 授权类型:设置调用方名单是白名单还是黑名单。
四、自定义异常处理
当请求被Sentinel拦截时,会抛出BlockException异常。为了更好地向调用方提供错误信息,可以自定义异常处理逻辑。
实现BlockExceptionHandler接口,并重写其handle方法。该方法有三个参数:HttpServletRequest request、HttpServletResponse response和BlockException e。其中,BlockException是Sentinel拦截时抛出的异常,包含多个不同的子类,如FlowException(限流异常)、DegradeException(降级异常)等。根据异常的类型,可以返回不同的错误信息和状态码。
五、规则持久化
Sentinel默认将规则保存在内存中,重启服务后规则会丢失。为了实现规则的持久化,可以采用以下两种方式:
- Pull模式:Sentinel控制台将配置的规则推送到Sentinel客户端,客户端将配置规则保存在本地文件或数据库中,以后会定时去本地文件或数据库中查询,更新本地规则。
- Push模式:Sentinel控制台将配置规则推送到远程配置中心(如Nacos),Sentinel客户端监听远程配置中心,获取配置变更的推送消息,完成本地配置更新。
通过以上方式,可以实现Sentinel授权规则的持久化,确保规则在服务重启后仍然有效。
综上所述,Sentinel的授权规则是一种强大的访问控制机制,可以根据请求方的来源进行细粒度的控制。通过自定义请求来源的获取方式、配置授权规则以及自定义异常处理逻辑,可以实现对服务调用方的有效管理和控制。
黑名单
自定义请求解析器,用于解析请求参数并自动注入到 Sentinel 上下文中
// Sentinel 授权规则的请求参数自定义解析器
@Component
public class MyRequestOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest httpServletRequest) {
return httpServletRequest.getParameter("myp1");
}
}授权规则信息:
- 资源名为
test3 - 流控应用为
1,5 - 授权类型为
黑名单
请求http://localhost:8080/api/v1/test3?myp1=白名单,请求http://localhost:8080/api/v1/test3?myp1=1黑名单
白名单
和黑名单用法类似。
规则持久化
介绍
Sentinel规则持久化是指将配置在Sentinel控制台的流量控制、熔断降级等规则存储到持久化存储系统中,使得即使服务重启或者Sentinel守护进程重启,规则也能自动恢复,无需重新手动配置。以下是对Sentinel规则持久化的详细介绍:
一、持久化方式
- Push模式:
- 规则中心统一推送,客户端通过注册监听器的方式时刻监听变化。例如,使用Nacos、Zookeeper等配置中心。
- 当规则出现修改时,Sentinel控制台将规则推送至客户端,接着客户端会更新内存中的信息,并且将这部分数据写入到本地磁盘文件(或其他持久化存储)进行持久化保存。但这种方式是基于定时更新实现的,所以规则更新会存在延迟。
- 当采用Push模式时,规则是存储在远程配置中心的,因此当出现服务迁移时,不影响规则信息。这种方式有更好的实时性和一致性保证,是生产环境下一般采用的方式。
- Pull模式:
- 客户端定期轮询拉取规则。
- 这种方式简单且无任何依赖,但不保证一致性,实时性也无法保证。此外,拉取过于频繁也可能会有性能问题。
二、Push模式实现示例(以Nacos为例)
引入依赖:
在需要持久化规则的服务中引入Sentinel监听Nacos的依赖。例如,在
pom.xml中添加以下依赖:xml<dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-datasource-nacos</artifactId> </dependency>配置Nacos地址:
在服务中的
application.yml或bootstrap.yml文件中配置Nacos地址及监听的配置信息。例如:yamlspring: cloud: sentinel: datasource: flow: nacos: server-addr: localhost:8848 # Nacos地址 dataId: orderservice-flow-rules # 数据ID groupId: SENTINEL_GROUP # 分组ID rule-type: flow # 规则类型修改Sentinel控制台源码(如果需要):
如果Sentinel控制台默认不支持Nacos持久化,则需要修改其源码。具体步骤包括解压源码包、修改
pom.xml文件中的Nacos依赖、将测试包下的Nacos支持代码拷贝到主包下、修改Nacos地址配置、配置Nacos数据源以及修改前端页面等。启动服务:
启动修改后的Sentinel控制台和需要持久化规则的服务。服务会从Nacos中读取规则并应用到Sentinel框架内。
测试:
在Sentinel控制台中创建或更新规则后,这些规则会被推送到Nacos中保存。客户端启动时会从Nacos中读取规则。可以测试重启服务后规则是否仍然有效,以验证持久化是否成功。
三、注意事项
规则一致性:
在Push模式下,由于规则是统一推送和监听的,因此可以保证规则的一致性。但在Pull模式下,由于客户端是定期轮询拉取规则的,因此可能存在规则不一致的情况。
性能开销:
Push模式需要客户端监听远程配置中心的变化并实时更新本地规则,这可能会增加一定的性能开销。而Pull模式则相对简单,但可能会因为频繁拉取规则而影响性能。
服务迁移:
当采用Push模式时,由于规则是存储在远程配置中心的,因此服务迁移时不需要迁移规则文件。而采用Pull模式时,则需要确保规则文件在服务迁移时能够正确迁移。
版本兼容性:
在升级Sentinel或相关依赖时,需要注意版本兼容性问题。不同版本的Sentinel可能支持不同的持久化方式和配置方式。
综上所述,Sentinel规则持久化是确保服务稳定性和可用性的重要手段之一。在生产环境下,建议采用Push模式进行规则持久化,并结合具体的业务场景和需求选择合适的配置中心和持久化存储方式。
配置
pom 依赖配置
<!-- Sentinel 持久化配置到 Nacos 依赖 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>application.properties 配置
# Sentinel 持久化配置到 Nacos 配置
spring.cloud.sentinel.datasource.ds1.nacos.server-addr=localhost:8848
spring.cloud.sentinel.datasource.ds1.nacos.group-id=DEFAULT_GROUP
spring.cloud.sentinel.datasource.ds1.nacos.data-id=${spring.application.name}
spring.cloud.sentinel.datasource.ds1.nacos..data-type=json
# flow:流控规则。这是 Sentinel 最核心、最直观的一种规则,主要用于控制请求的 QPS(每秒查询率)或并发线程数,以防止系统被过大的流量压垮。
# degrade:熔断规则。当系统的某个资源不稳定或出现故障时,为了防止故障的进一步扩散,可以使用熔断规则来快速失败这个资源的请求。熔断规则通常基于一些条件(如慢调用比例、异常比例或异常数)来触发。
# param-flow:热点规则。热点规则用于对某个资源中的某个或某些参数进行单独的流控。这可以帮助系统保护那些因为某些特殊参数值而导致的高并发请求。
# system:系统规则。系统规则是从系统的整体角度出发,对系统的入口流量、CPU 使用率、线程数等指标进行整体控制,以防止系统整体过载。
# authority:授权规则。授权规则用于对资源的访问进行黑白名单控制。这可以帮助系统实现细粒度的访问控制。
spring.cloud.sentinel.datasource.ds1.nacos..rule-type=flow登录 Nacos 创建 Sentinel 规则的配置如下:
Data ID 为 demo-springcloud-gateway(demo-springcloud-gateway 为微服务名称)
Group 为 DEFAULT_GROUP
Format 为 JSON
Configuration Content 为
json[{ "resource": "test3", "limitApp": "default", "grade": 1, "count": 1, "strategy": 0, "controlBehavior": 0, "clusterMode": false },{ "resource": "/api/v1/test1", "limitApp": "default", "grade": 1, "count": 2, "strategy": 0, "controlBehavior": 0, "clusterMode": false }]
请求http://localhost:8080/api/v1/test1和http://localhost:8080/api/v1/test3测试效果。
和 SpringCloud Gateway 集成
todo
https://github.com/alibaba/Sentinel/wiki/%E7%BD%91%E5%85%B3%E9%99%90%E6%B5%81